Hi there!
This is a place where I store my notes.
这个地方存放了我的笔记。
Algorithms
Useful links:
CodeTop
class Solution {
public:
int lengthOfLongestSubstring(string s) {
vector<int> idx(128, -1);
int l = 0, ans = 0;
for (int r = 0; r < s.size(); r ++) {
if (idx[s[r]] >= l) {
l = idx[s[r]] + 1;
}
idx[s[r]] = r;
ans = max(ans, r - l + 1);
}
return ans;
}
};
class Node {
public:
int k, v;
Node *pre, *nex;
Node() : k(0), v(0), pre(nullptr), nex(nullptr) {}
Node(int _k, int _v) : k(_k), v(_v), pre(nullptr), nex(nullptr) {}
};
class LRUCache {
Node *head, *tail;
int cap;
unordered_map<int, Node *> store;
public:
LRUCache(int capacity) : cap(capacity) {
// dummy head & tail
head = new Node();
tail = new Node();
head->nex = tail;
tail->pre = head;
}
int get(int key) {
if (!store.count(key)) {
return -1;
}
Node *n = store[key];
moveToHead(n);
return n->v;
}
void put(int key, int value) {
if (store.count(key)) {
Node *n = store[key];
n->v = value;
moveToHead(n);
return;
}
if (store.size() >= cap) {
Node *toRemove = tail->pre;
store.erase(toRemove->k);
removeNode(toRemove);
}
Node *n = new Node(key, value);
moveToHead(n);
store[key] = n;
}
void removeNode(Node *n) {
n->pre->nex = n->nex;
n->nex->pre = n->pre;
}
void moveToHead(Node *n) {
if ((n->pre && n->pre->nex == n) || (n->nex && n->nex->pre == n)) {
removeNode(n);
}
n->pre = head;
n->nex = head->nex;
head->nex->pre = n;
head->nex = n;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *pre = nullptr;
ListNode *cur = head;
while (cur) {
ListNode *next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
return pre;
}
};
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
int n = nums.size();
int minVal = *min_element(nums.begin(), nums.end());
int maxVal = *max_element(nums.begin(), nums.end());
vector<int> bucket(maxVal - minVal + 1, 0);
for (int i = 0; i < n; i++) {
bucket[nums[i] - minVal]++;
}
// 每个桶可能不止一个
int count = 0;
for (int i = bucket.size() - 1; i >= 0; i--) {
count += bucket[i];
// 这个桶加完后超过 k 表示已经找到了
if (count >= k) {
return i + minVal;
}
}
return -1;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
if (head == nullptr) return head;
int i = k;
ListNode *cur = head;
while (cur && --i > 0) { // --i,提前一格退出,那么 cur 指向最后一个
cur = cur->next;
}
// no more than k;
if (cur == nullptr) return head;
ListNode *nextHead = cur->next;
ListNode *pre = nullptr;
cur = head;
while (cur != nextHead) {
ListNode *tmp = cur->next;
cur->next = pre;
pre = cur;
cur = tmp;
}
head->next = reverseKGroup(nextHead, k);
return pre;
}
};
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<vector<int>> ans;
for (int k = 0; k < nums.size() - 2; k++) {
if (nums[k] > 0) break;
if (k > 0 && nums[k] == nums[k - 1]) continue;
int l = k + 1, r = nums.size() - 1;
while (l < r) {
int sum = nums[l] + nums[r] + nums[k];
if (sum == 0) {
ans.push_back({nums[l], nums[r], nums[k]});
while (l < r && nums[l] == nums[++l]); // && nums[l] == nums[++l] 先加 l + 1,然后跳过所有相等的
while (l < r && nums[r] == nums[--r]); // 同上
}
if (sum < 0)
while (l < r && nums[l] == nums[++l]);
if (sum > 0)
while (l < r && nums[r] == nums[--r]);
}
}
return ans;
}
};
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int dp = nums[0];
int ans = nums[0];
for (int i = 1; i < nums.size(); i ++) {
dp = max(dp + nums[i], nums[i]);
ans = max(dp, ans);
}
return ans;
}
};
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {
quick_sort(nums, 0, nums.size() - 1);
return nums;
}
void quick_sort(vector<int>& nums, int l, int r) {
if (l < r) {
int pivot = partition(nums, l, r);
quick_sort(nums, l, pivot - 1);
quick_sort(nums, pivot + 1, r);
}
}
int partition(vector<int>& nums, int l, int r) {
int key = nums[l];
while (l < r) {
while (l < r && nums[r] >= key) r --;
nums[l] = nums[r];
while (l < r && nums[l] <= key) l ++;
nums[r] = nums[l];
}
nums[l] = key;
return l;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* dummy = new ListNode();
ListNode* cur = dummy;
ListNode* cur1 = list1;
ListNode* cur2 = list2;
while (cur1 || cur2) {
if (!cur1) {
cur->next = cur2;
cur = cur->next;
cur2 = cur2->next;
continue;
}
if (!cur2) {
cur->next = cur1;
cur = cur->next;
cur1 = cur1->next;
continue;
}
if (cur1->val < cur2->val) {
cur->next = cur1;
cur = cur->next;
cur1 = cur1->next;
} else {
cur->next = cur2;
cur = cur->next;
cur2 = cur2->next;
}
}
return dummy->next;
}
};
class Solution {
public:
// dp[i, j] = dp[i + 1, j - 1] && (s[i] == s[j])
string longestPalindrome(string s) {
bool dp[1009][1009];
int maxAns = 0;
int l = 0;
// 注意递推方程的性质,i 依赖 i + 1,j 依赖 j - 1
for (int j = 0; j < s.length(); j++) {
for (int i = 0; i <= j; i++) {
if (i == j) {
dp[i][j] = true;
} else if (i == j - 1 && s[i] == s[j]) {
dp[i][j] = true;
} else {
dp[i][j] = dp[i + 1][j - 1] && s[i] == s[j];
}
if (dp[i][j] && j - i + 1 > maxAns) {
maxAns = j - i + 1;
l = i;
}
}
}
return s.substr(l, maxAns);
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> ret;
if (!root) {
return ret;
}
queue<TreeNode *> q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size(); // 这里得保存,不然在 for 循环中 q 会持续变大
ret.push_back(vector<int>());
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front();
q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return ret;
}
};
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> numMap;
int n = nums.size();
for (int i = 0; i < n; i++) {
int complement = target - nums[i];
if (numMap.count(complement)) {
return {numMap[complement], i};
}
numMap[nums[i]] = i;
}
return {};
}
};
class Solution {
public:
int search(vector<int>& nums, int target) {
int n = nums.size();
int l = 0, r = n - 1;
while (l <= r) {
int mid = (l + r) / 2;
if (nums[mid] == target) return mid;
// 检查 mid 在哪个有序区间内
if (nums[0] <= nums[mid]) {
// 第一个有序区间内,检查是否可以缩减到 0 ~ mid 范围内
if (nums[0] <= target && target < nums[mid]) {
r = mid - 1;
} else {
l = mid + 1;
}
} else {
// 第二个有序区间内,检查是否可以缩减到 mid + 1 ~ n - 1 范围内
if (nums[mid] < target && target <= nums[n - 1]) {
l = mid + 1;
} else {
r = mid - 1;
}
}
}
return -1;
}
};
class Solution {
int direction[4][2] = {{0, 1}, {1, 0}, {-1, 0}, {0, -1}};
public:
// 常规写法
int numIslands(vector<vector<char>>& grid) {
int ans = 0;
bool mark[300][300];
memset(mark, 0, sizeof(mark));
for (int i = 0; i < grid.size(); i++) {
for (int j = 0; j < grid[i].size(); j++) {
if (grid[i][j] == '0' || mark[i][j]) {
continue;
}
dfs(mark, grid, i, j);
ans++;
}
}
return ans;
}
void dfs(bool mark[300][300], vector<vector<char>>& grid, int i, int j) {
if (i < 0 || j < 0 || i >= grid.size() || j >= grid[i].size() ||
grid[i][j] == '0') {
return;
}
if (mark[i][j]) {
return;
}
mark[i][j] = true;
for (auto& d : direction) {
int di = d[0];
int dj = d[1];
dfs(mark, grid, i + di, j + dj);
}
}
};
class Solution {
public:
vector<int> vis;
vector<int> path;
void dfs(vector<vector<int>>& ans, vector<int>& nums, int x) {
if (x >= nums.size()) {
ans.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (vis[i]) continue;
vis[i] = 1;
path.push_back(nums[i]);
dfs(ans, nums, x + 1);
vis[i] = 0;
path.pop_back();
}
}
// 回溯板子题,来自题解 dfs 暴搜,排列组合
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> ans;
vis.resize(nums.size(), 0);
dfs(ans, nums, 0);
return ans;
}
};
class Solution {
public:
bool isValid(string s) {
stack<char> t;
for (char c : s) {
if (c == '(' || c == '{' || c == '[') {
t.push(c);
continue;
}
if (t.empty()) {
return false;
}
char l = t.top();
t.pop();
if (c == ')' && l != '(') return false;
if (c == ']' && l != '[') return false;
if (c == '}' && l != '{') return false;
}
return t.empty(); // 最后的栈一定是空的
}
};
class Solution {
public:
// O(N)
// 先有股票最低点,然后才有可能有比之前还多的利润
int maxProfit(vector<int>& prices) {
int buy = 0, profit = 0;
for (int i = 0; i < prices.size(); ++i) {
if (prices[i] < prices[buy]) {
buy = i;
}
int gain = prices[i] - prices[buy];
if (gain > profit) {
profit = gain;
}
}
return profit;
}
};
class Solution {
public:
// 常规写法
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
vector<int> ans;
int i = 0, j = 0;
while (i < m || j < n) {
if (j >= n) {
ans.push_back(nums1[i]);
i++;
continue;
}
if (i >= m) {
ans.push_back(nums2[j]);
j++;
continue;
}
if (nums1[i] <= nums2[j]) {
ans.push_back(nums1[i]);
i++;
} else {
ans.push_back(nums2[j]);
j++;
}
}
copy(ans.begin(), ans.end(), nums1.begin());
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode *root) {
vector<vector<int>> ans;
if (!root) {
return ans;
}
queue<TreeNode *> q;
q.push(root);
bool flag = false;
while (!q.empty()) {
vector<int> l;
int lsize = q.size();
for (int i = 0; i < lsize; i++) {
TreeNode *f = q.front();
q.pop();
l.push_back(f->val);
if (f->left) q.push(f->left);
if (f->right) q.push(f->right);
}
if (flag) {
reverse(l.begin(), l.end()); // 反转
flag = false;
} else {
flag = true;
}
ans.push_back(l);
}
return ans;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
unordered_set<ListNode *> s;
while (head) {
if (s.count(head)) {
return true;
}
s.insert(head);
head = head->next;
}
return false;
}
};
// TODO: 快慢指针
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || !root) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
if (!left) return right;
return left;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int left, int right) {
ListNode *dummy = new ListNode();
dummy->next = head;
ListNode *pre = dummy;
for (int i = 0; i < left - 1; i++) pre = pre->next;
ListNode *subHead = pre->next;
ListNode *subPre = nullptr;
ListNode *subCur = subHead;
ListNode *next;
for (int i = 0; i < right - left + 1; i++) {
next = subCur->next;
subCur->next = subPre;
subPre = subCur;
subCur = next;
}
ListNode *subTail = subPre;
pre->next = subTail;
subHead->next = subCur;
return dummy->next;
}
};
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
vector<int> ans;
if (matrix.empty()) return ans; // 若数组为空,直接返回答案
int u = 0; // 上边界
int l = 0; // 左边界
int d = matrix.size() - 1; // 下边界
int r = matrix[0].size() - 1; // 右边界
while (true) {
for (int i = l; i <= r; ++i) ans.push_back(matrix[u][i]); // 向右移动直到最右
if (++u > d) break; // 增加上边界,上边界大于下边界,退出
for (int i = u; i <= d; ++i) ans.push_back(matrix[i][r]); // 向下
if (--r < l) break; // 重新设定有边界
for (int i = r; i >= l; --i) ans.push_back(matrix[d][i]); // 向左
if (--d < u) break; // 重新设定下边界
for (int i = d; i >= u; --i) ans.push_back(matrix[i][l]); // 向上
if (++l > r) break; // 重新设定左边界
}
return ans;
}
};
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
// dp[i] = max(dp[j], 0 <= j < i and nums[i] > nums[j]) + 1
int dp[2501];
fill_n(dp, 2501, 1);
int ans = 1;
for (int i = 0; i < nums.size(); i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
ans = max(ans, dp[i]);
}
return ans;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
auto cmp = [](ListNode* a, ListNode* b) { return a->val > b->val };
priority_queue<ListNode*, vector<ListNode*>,
decltype(cmp)>
pq(cmp);
ListNode* dummy = new ListNode();
ListNode* cur = dummy;
for (auto node : lists) {
if (node) pq.push(node);
}
while (!pq.empty()) {
auto node = pq.top();
pq.pop();
cur->next = node;
cur = cur->next;
if (node->next) pq.push(node->next);
}
return dummy->next;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
void reorderList(ListNode* head) {
if (!head) {
return;
}
vector<ListNode *> s;
ListNode *cur = head;
int n = 0;
while (cur) {
s.push_back(cur);
cur = cur->next;
n++;
}
// 双指针
int i = 0, j = n - 1;
while (i < j) {
s[i]->next = s[j];
i++;
if (i == j) break;
s[j]->next = s[i];
j--;
}
s[i]->next = nullptr;
}
};
class Solution {
public:
string addStrings(string num1, string num2) {
string ans = "";
int c1 = (int)num1.size();
int c2 = (int)num2.size();
int cm = max(c1, c2);
int carry = 0;
for (int i = 1; i <= cm; i++) {
int sum = 0;
if (c1 - i >= 0) {
sum += num1[c1 - i] - '0';
}
if (c2 - i >= 0) {
sum += num2[c2 - i] - '0';
}
sum += carry;
ans.push_back('0' + (sum % 10));
carry = sum / 10;
}
// 最后记得带上 carry
if (carry) {
ans.push_back('0' + carry);
}
reverse(ans.begin(), ans.end());
return ans;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *cur1 = headA; // headA -> tailA -> headB -> tailB;
ListNode *cur2 = headB; // headB -> tailB -> headA -> tailA;
while (cur1 != cur2) {
if (cur1)
cur1 = cur1->next;
else
cur1 = headB;
if (cur2)
cur2 = cur2->next;
else
cur2 = headA;
}
return cur1;
}
};
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> ans;
sort(intervals.begin(), intervals.end());
int n = intervals.size();
// [1,2][2,3][4,5] => [1,2][1,3](插入 [1,3])[4,5]
// [1,4][2,3] => [1,4][1,4]
// 遍历到倒数第二个
for (int i = 0; i < n-1; i ++) {
// 前一个末尾比后一个开头大,把后一个开头改成前一个开头
if (intervals[i][1] >= intervals[i+1][0]) {
intervals[i+1][0] = intervals[i][0];
}
// 前一个末尾比后一个末尾还大,那把后一个末尾也改成前一个末尾
if (intervals[i][1] >= intervals[i+1][1]) {
intervals[i+1][1] = intervals[i][1];
}
// 出现了空隙,说明这个没办法继续合并了
if (intervals[i][1] < intervals[i+1][0]) {
ans.push_back(intervals[i]);
}
}
// 最后一个一定是合并的结果
ans.push_back(intervals[n-1]);
return ans;
}
};
class Solution {
public:
int trap(vector<int>& height) {
// lmax
// | rmax
// | # |
// ————
// l r
int l = 0, r = h.size() - 1, lmax = -1, rmax = -1, ans = 0;
while (l < r) {
lmax = max(lmax, h[l]);
rmax = max(rmax, h[r]);
ans += (lmax < rmax) ? lmax - h[l++] : rmax - h[r--];
}
return ans;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int ans = -1001;
int maxPathSum(TreeNode* root) {
treeSum(root);
return ans;
}
int treeSum(TreeNode *root) {
int sumL = 0, sumR = 0;
if (root->left) {
sumL = treeSum(root->left);
}
if (root->right) {
sumR = treeSum(root->right);
}
// ans 来自 max(root->val, root->val + sumL, root->val + sumR, root->val
// + sumL + sumR)
ans = max(ans, max({root->val, root->val + sumL, root->val + sumR,
root->val + sumL + sumR}));
// 但只能返回给上层 max(root->val, root->val + sumL, root->val + sumR)
return max({root->val, root->val + sumL, root->val + sumR});
}
};
class Solution {
public:
int minDistance(string word1, string word2) {
int n1 = word1.size();
int n2 = word2.size();
if (n1 * n2 == 0) return max(n1, n2);
// dp[i][j] 表示 word1 中 [0, i) 和 word2 中 [0, j) (注意是不包括 i, j)的最短编辑距离
int dp[501][501];
memset(dp, 0, sizeof(dp));
for (int i = 0; i < 501; i ++) {
dp[i][0] = i;
dp[0][i] = i;
}
for (int i = 1; i <= n1; i ++)
for (int j = 1; j <= n2; j ++) {
int left = dp[i-1][j] + 1;
int down = dp[i][j-1] + 1;
int left_down = dp[i-1][j-1];
if (word1[i-1] != word2[j-1]) // 判断末尾的字符是否相等,相等则不用修改
left_down ++;
dp[i][j] = min({left, down, left_down});
}
return dp[n1][n2];
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if (!head) {
return nullptr;
}
unordered_set<ListNode *> s;
ListNode *cur = head;
while (cur) {
if (s.count(cur)) return cur;
s.insert(cur);
cur = cur->next;
}
return nullptr;
}
};
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
// dp[i][j] = dp[i-1][j-1] + 1, text1[i -1] == text2[j - 1];
// dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]), text1[i -1] != text2[j - 1];
int m = text1.length(), n = text2.length();
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++) {
char c1 = text1.at(i - 1);
for (int j = 1; j <= n; j++) {
char c2 = text2.at(j - 1);
if (c1 == c2) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummy = new ListNode();
dummy->next = head;
ListNode* cur = head;
int count = 0;
while (cur) {
count++;
cur = cur->next;
}
ListNode* pre = dummy;
cur = head;
for (int i = 0; i < count - n; i++) {
pre = cur;
cur = cur->next;
}
pre->next = cur->next;
return dummy->next;
}
};
class Solution {
public:
vector<string> ans;
vector<string> parts;
vector<string> restoreIpAddresses(string s) {
dfs(s, 0);
return ans;
}
void dfs(string raw, int pos) {
if (pos == raw.size()) {
if (parts.size() == 4) {
string a = parts[0];
for (int i = 1; i < parts.size(); i++) {
a = a + "." + parts[i];
}
ans.push_back(a);
}
return;
}
if (raw[pos] == '0') {
parts.push_back("0");
dfs(raw, pos + 1);
parts.pop_back();
return;
}
int n = 0;
for (int i = pos; i < raw.size(); i++) {
n++;
string sub = raw.substr(pos, n);
if (stoi(sub) <= 255) {
parts.push_back(sub);
dfs(raw, pos + n);
parts.pop_back();
}
if (n == 3) break;
}
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head) {
return head;
}
ListNode* dummy = new ListNode(0, head);
ListNode* cur = dummy;
while (cur->next && cur->next->next) {
if (cur->next->val == cur->next->next->val) {
int x = cur->next->val;
while (cur->next && cur->next->val == x) {
cur->next = cur->next->next;
}
} else {
cur = cur->next;
}
}
return dummy->next;
}
};
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
int i = 0, j = 0, k = 0, pre = 0, cur = 0, n1 = nums1.size(), n2 = nums2.size();
int m = n1 + n2;
int mid = m >> 1;
while (k <= mid) {
pre = cur;
if (i < n1 && j < n2) {
if (nums1[i] < nums2[j]) {
cur = nums1[i];
i++;
} else {
cur = nums2[j];
j++;
}
} else if (i < n1) {
cur = nums1[i];
i++;
} else {
cur = nums2[j];
j++;
}
k++;
}
if (m % 2 == 0) {
return (float)(pre + cur) / 2;
}
return (float)cur;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
vector<int> ans;
if (root == nullptr) return ans;
deque<TreeNode*> q;
q.push_back(root);
while (!q.empty()) {
int n = q.size();
for (int i = 0; i < n; i ++) {
TreeNode* front = q.front();
q.pop_front();
if (i == n-1) {
ans.push_back(front->val);
}
if (front->left) {
q.push_back(front->left);
}
if (front->right) {
q.push_back(front->right);
}
}
}
return ans;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> ans;
vector<int> inorderTraversal(TreeNode* root) {
if (!root) {
return ans;
}
inorderTraversal(root->left);
ans.push_back(root->val);
inorderTraversal(root->right);
return ans;
}
};
class Solution {
public:
int search(vector<int>& nums, int target) {
int l = 0, r = nums.size();
while (l < r) {
int mid = l + ((r - l) >> 1);
if (nums[mid] == target) return mid;
if (nums[mid] > target) {
r = mid;
} else {
l = mid + 1;
}
}
return -1;
}
};
class MyQueue {
public:
stack<int> s1;
stack<int> s2;
MyQueue() {}
void push(int x) { s1.push(x); }
int pop() {
while (!s1.empty()) {
s2.push(s1.top());
s1.pop();
}
int ret = s2.top();
s2.pop();
while (!s2.empty()) {
s1.push(s2.top());
s2.pop();
}
return ret;
}
int peek() {
while (!s1.empty()) {
s2.push(s1.top());
s1.pop();
}
int ret = s2.top();
while (!s2.empty()) {
s1.push(s2.top());
s2.pop();
}
return ret;
}
bool empty() { return s1.empty(); }
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
class Solution {
public:
vector<string> ans;
string op;
void dfs(int l, int r) {
if (l == 0 && r == 0) {
ans.push_back(op);
return;
}
if (l > 0) {
op.push_back('(');
dfs(l - 1, r + 1);
op.pop_back();
}
if (r > 0) {
op.push_back(')');
dfs(l, r - 1);
op.pop_back();
}
}
vector<string> generateParenthesis(int n) {
dfs(n, 0);
return ans;
}
};
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int n = nums.size() - 1;
while (n > 0 && nums[n] <= nums[n - 1]) {
n--;
}
if (n == 0) {
reverse(nums.begin(), nums.end());
} else {
int i = n;
while (i < nums.size() && nums[i] > nums[n - 1]) {
i++;
}
swap(nums[n - 1], nums[i - 1]);
reverse(nums.begin() + n, nums.end());
}
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
// merge sort
ListNode* sortList(ListNode* head) {
if (head == nullptr || head->next == nullptr) return head;
// find the middle node
ListNode *fast = head->next, *slow = head;
while (fast != nullptr && fast->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
ListNode* r = slow->next;
slow->next = nullptr;
return merge(sortList(head), sortList(r));
}
ListNode* merge(ListNode* l, ListNode* r) {
ListNode* dummy = new ListNode();
ListNode* c = dummy;
while (l != nullptr && r != nullptr) {
if (l->val <= r->val) {
c->next = l;
c = c->next;
l = l->next;
} else {
c->next = r;
c = c->next;
r = r->next;
}
}
if (l != nullptr) {
c->next = l;
}
if (r != nullptr) {
c->next = r;
}
return dummy->next;
}
};
class Solution {
public:
vector<string> split(string s, string delimiter) {
size_t start = 0, end, d_len = delimiter.size();
vector<string> ans;
while ((end = s.find(delimiter, start)) != string::npos) {
ans.push_back(s.substr(start, end - start));
start = end + d_len;
}
ans.push_back(s.substr(start));
return ans;
}
int compareVersion(string version1, string version2) {
vector<string> v1 = split(version1, ".");
vector<string> v2 = split(version2, ".");
for (int i = 0; i < v1.size() || i < v2.size(); i ++) {
int vv1 = 0, vv2 = 0;
if (i < v1.size()) {
vv1 = stoi(v1[i]);
}
if (i < v2.size()) {
vv2 = stoi(v2[i]);
}
if (vv1 > vv2) {
return 1;
}
if (vv1 < vv2) {
return -1;
}
}
return 0;
}
};
class Solution {
public:
int mySqrt(int x) {
long long l = 0, r = x;
while (l < r) {
long long mid = (l + r + 1) / 2;
if (x >= mid * mid) {
l = mid;
} else {
r = mid - 1;
}
}
return r;
}
};
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
int n = nums.size();
priority_queue<pair<int, int>> q;
for (int i = 0; i < k; ++i) {
q.emplace(nums[i], i);
}
vector<int> ans = {q.top().first};
for (int i = 1; i + k <= n; i++) {
q.emplace(nums[i + k - 1], i + k - 1);
while (q.top().second < i) {
q.pop();
}
ans.push_back(q.top().first);
}
return ans;
}
};
class Solution {
public:
int myAtoi(string s) {
int res = 0, sign = 1, start = 0, boundary = INT_MAX / 10;
if (s.empty()) return 0;
for (; start < s.size() && s[start] == ' '; start++);
if (s[start] == '-') {
start++;
sign = -1;
} else if (s[start] == '+') {
start++;
}
for (; start < s.size(); start++) {
if (s[start] < '0' || s[start] > '9') break;
if (res > boundary ||
res == boundary && (s[start] - '0') > (INT_MAX % 10))
return sign > 0 ? INT_MAX : INT_MIN;
res = (res * 10) + (s[start] - '0');
}
return res * sign;
}
};
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* dummy = new ListNode();
int carry = 0;
ListNode *c1 = l1, *c2 = l2, *c = dummy;
while (c1 != nullptr || c2 != nullptr) {
int sum = carry;
if (c1 != nullptr) {
sum += c1->val;
c1 = c1->next;
}
if (c2 != nullptr) {
sum += c2->val;
c2 = c2->next;
}
carry = sum / 10;
c->next = new ListNode(sum % 10);
c = c->next;
}
if (carry > 0) {
c->next = new ListNode(carry);
}
return dummy->next;
}
};
class Solution {
public:
int climbStairs(int n) {
int dp[50] = {0};
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i ++) {
dp[i] = dp[i - 2] + dp[i - 1];
}
return dp[n];
}
};
CodeWar
Books
Books notes and excerpts
Database System Concepts (Seventh Edition)
#12 Physical Storage Systems
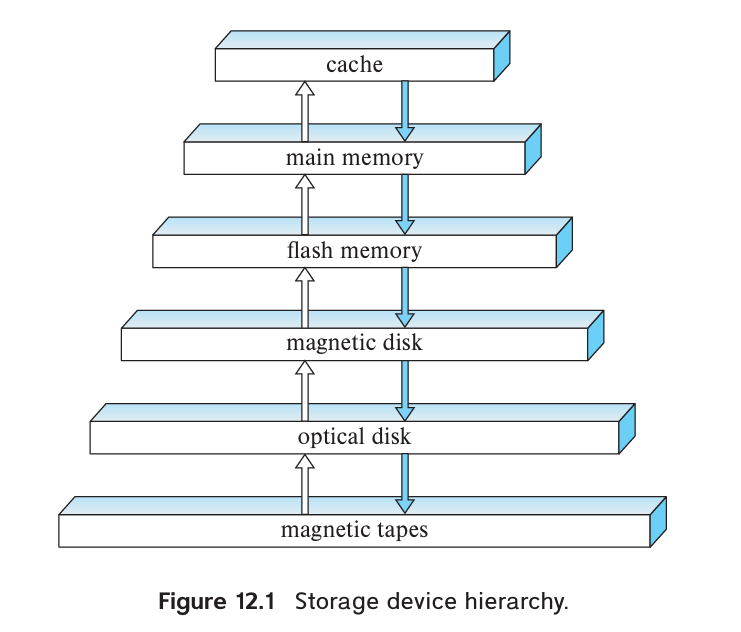
Media
- Cache
- Main memory
- Flash memory
- Magnetic-disk storage
- Optical storage
- Tape storage
Storage Interfaces
-
Serial ATA (SATA)
- SATA-3: nominally supports 6 GB/s, allowing data transfer speeds of up to 600 MB/s.
-
Serial Attached SCSI (SAS): typically used only in servers.
- SAS-3: nominally supports data transfer rates of 12 GB/s.
-
Non Volatile Memory Express (NVMe): logical interface standard developed to better support SSDs and is typically used with the PCIe interface.
-
Storage Area Network (SAN): large numbers of disks are connected by a high-speed network to a number of server computers. e.g. RAID.
- iSCSI: An interconnection technology allows SCSI commands to be sent over an IP network.
- Fiber Channel FC: supports transfer rates of 1.6 to 12 GB/s, depending on the version.
- InfiniBand: provides very low latency high-bandwidth network communication.
-
Network attached storage (NAS): provides a file system interface using networked file system protocols such as NFS or CIFS. e.g. cloud storage.
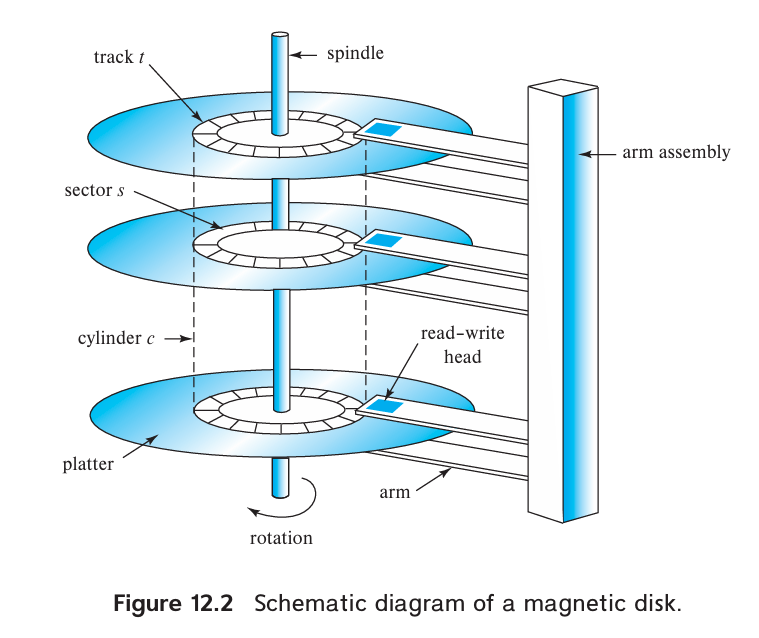
Magnetic Disks
Performance Measurement
- Access time: The time from when a read or write request is issued to when data transfer begins, mainly include seek time and rotational latency time.
- Seek time: The time for repositioning the arm. Typical seek times range from 2 to 20 milliseconds depending on how far the track is from the initial arm position. Average seek times currently range between 4 and 10 milliseconds, depending on the disk model.
- Rotational latency time: The time spent waiting for the sector to be accessed to appear under the head. Typically range from 2 to 5.5 milliseconds.
- Data-transfer rate: The rate at which data can be retrieved from or stored to the disk. Current disk systems support maximum transfer rates of 50 to 200 MB/s.
- IOPS: With a 4KB block size, current generation disks support between 50 and 200IOPS, depending on the model.
- Mean time to failure (MTTF): According to vendors’ claims, the mean time to failure of disks today ranges from 500,000 to 1,200,000 hours—about 57 to 136 years.
Flash Memory
- Erase block: Once written, a page of flash memory cannot be directly overwritten. It has to be erased and rewritten subsequently. The erase operation must be performed on a group of pages, called an erase block.
- Translation table: Flash memory systems limit the impact of both the slow erase speed and the update limits by mapping logical page numbers to physical page numbers. The page mapping is replicated in an in-memory translation table for quick access.
- Wear leveling: Distributing erase operations across physical blocks, usually performed transparently by flash-memory controllers.
- Flash translation layer: All the above actions are carried out by a layer of software called the flash translation layer; above this layer, flash storage looks identical to magnetic disk storage, pro viding the same page/sector-oriented interface.
Performance Measurement
- IOPS: Typical values in 2018 are about 10,000 random reads per second with4KB blocks, although some models support higher rates.
- QD-n: SSDs can support multiple random requests in parallel, with 32 parallel requests being commonly supported (QD-32); a flash disk with SATA interface supports nearly 100,000 random 4KB block reads in a second with 32 requests sent in parallel, while SSDs connected using NVMe PCIe can support over 350,000 random 4KB block reads per second.
- Data transfer rate: Typical rates for both sequential reads and sequential writes are 400 to 500 megabytes per second for SSDs with a SATA 3 interface, and 2 to 3 GB/s for SSDs using NVMe over the PCIe3.0x4 interface.
- Random block writes per second: Typical values in 2018 are about 40,000 random 4KB writes per second for QD-1 (without parallelism), and around 100,000 IOPS for QD-32.
#13 Data Storage Structures
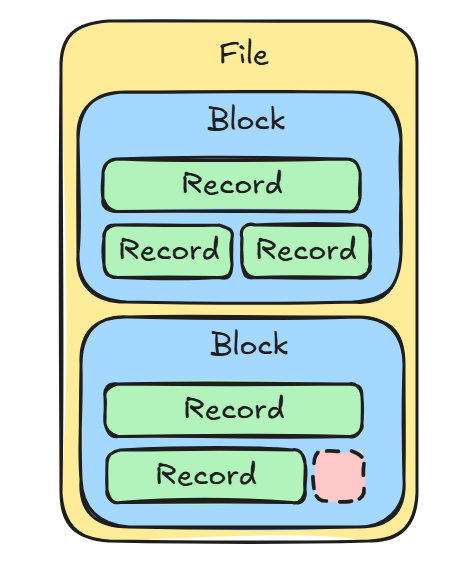
File Organization
File -> Block (fixed size, 4 to 8KB) -> Record (fixed or variable size)
Fixed-Length Records
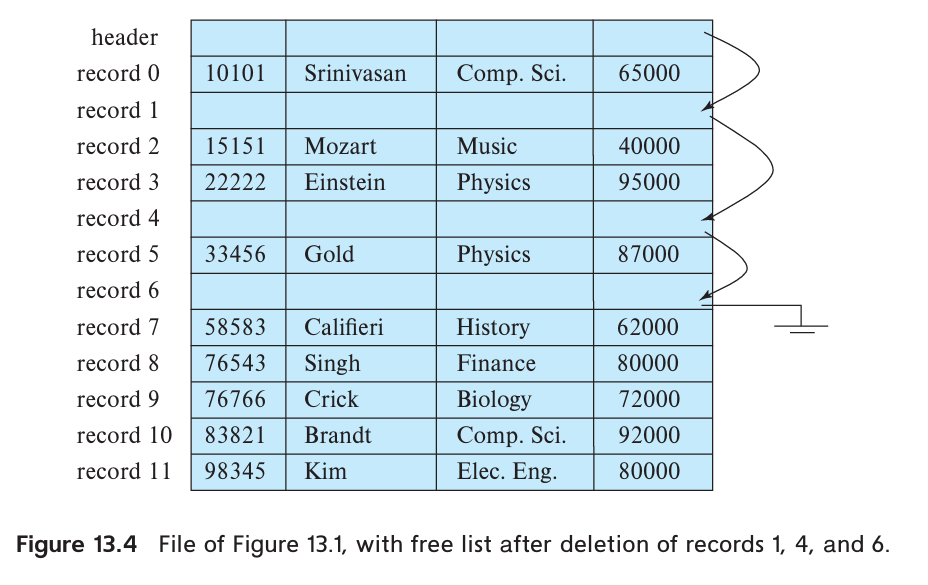
File header stores there is the address of the first record whose contents are deleted. The first record to store the address of the second available record, and so on. The deleted records thus form a linked list, which is often referred to as a free list.
Insertion and deletion can be easily done according to free list.
Variable-Length Records
For the presence of variable length fields, we use variable-length records.
A variable-length record looks like:
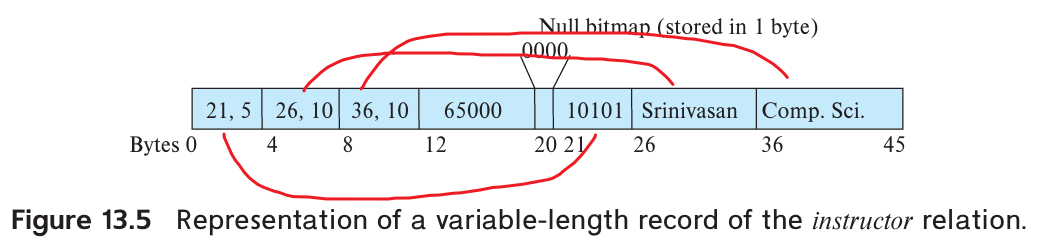
Variable-length attributes are represented in the initial part of the record by a pair (offset, length). The values for the variable-length attributes are stored consecutively, after the initial fixed-length part of the record.
Null bitmap indicates which attributes of the record have a null value.
The slotted-page structure is commonly used for organizing records within a block:
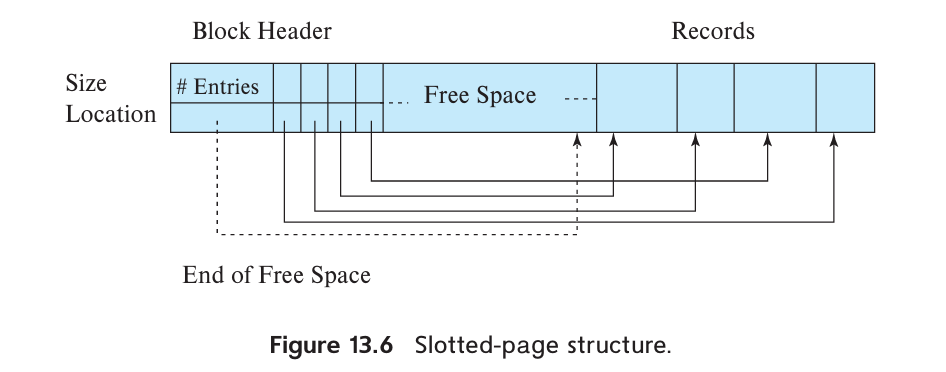
There is a header at the beginning of each block, containing the following information:
- The number of record entries in the header
- The end of free space in the block
- An array whose entries contain the location and size of each record
When a record is deleted, the space it occupied is freed up and its entry is marked as deleted (e.g. size set to -1). Additionally, the records in the block before the deleted record are shifted to fill the empty space created by the deletion. The cost of moving records is not too high because the block size is limited, typically around 4 to 8KB.
Storing Large Objects
Large objects may be stored either as files in a file system area managed by the database, or as file structures (e.g. B+ tree) stored in and managed by the database. A (logical) pointer to the object is then stored in the record containing the large object.
Organization of Records in Files
Heap file organization
In a heap file organization, a record can be stored anywhere in the file that corresponds to a relation. Once placed in a specific location, the record is typically not moved.
To implementing efficient insertion, most database use a space-efficient data structure called a free-space map to track which blocks have free space to store records.
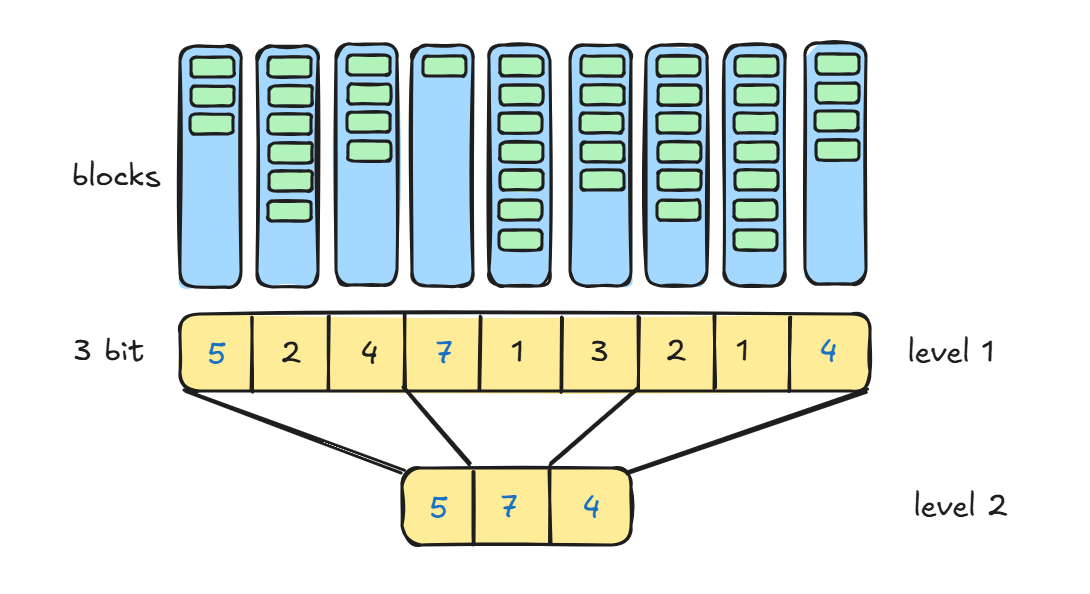
The free-space map is commonly represented by an array containing 1 entry for each block in the relation. Each entry represents a fraction f such that at least a fraction f of the space in the block is free. Assume that 3 bits are used to store the occupancy fraction; the value at position i should be divide by 8 to get the free-space fraction for block i.
To find a block to store a new record of a given size, the database can scan the free-space map to find a block that has enough free space to store that record. If there is no such block, a new block is allocated for the relation.
For large files, it can still be slow to scan free-space map. To further speed up the task of locating a block with sufficient free space, we can create a second-level free-space map, which has, say 1 entry for every 100 entries for the main free-space map. That 1 entry stores the maximum value amongst the 100 entries in the main free-space map that it corresponds to. (Seems like a skip list :D) We can create more levels beyond the second level, using the same idea.
Sequential file organization
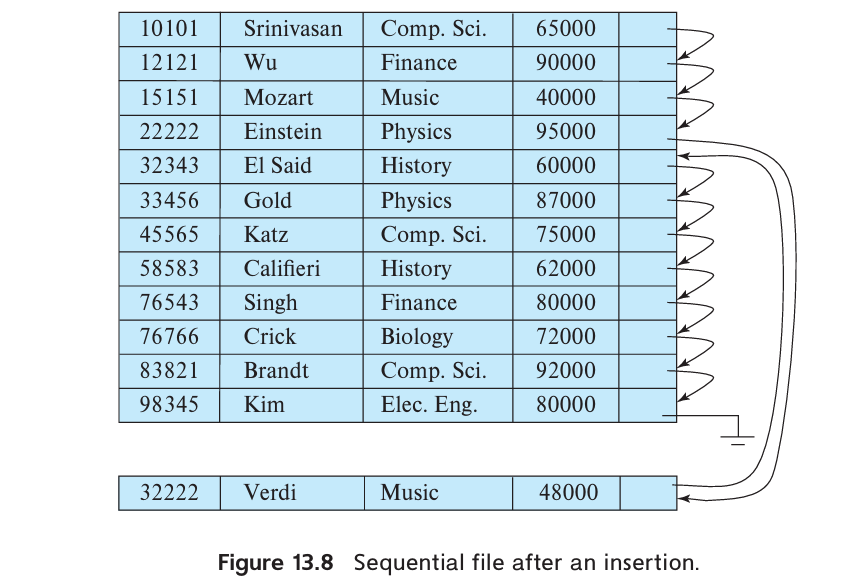
A sequential file is designed for efficient processing of records in sorted order based on some search key. A search key is any attribute or set of attributes. To permit fast retrieval of records in search-key order, we chain together records by pointers. The pointer in each record points to the next record in search-key order. Furthermore, to minimize the number of block accesses in sequential file processing, we store records physically in search-key order, or as close to search-key order as possible.
Maintaining physical sequential order is difficult when inserting or deleting records, as moving many records due to a single change is costly.
For insertion, we apply two rules:
- Locate the record in the file that precedes the record to be inserted in search key order.
- If there is available space in the same block, insert the new record there. Otherwise, insert the new record in an overflow block. In either case, adjust the pointers so as to chain together the records in search-key order.
Reorganizing is still necessary if the overflow blocks become too large. To keep the correspondence between search-key order and physical order. (B+-tree file organization provides efficient ordered access even if there are many inserts, deletes, without requiring expensive reorganizations).
Multitable clustering file organization
Multitable clustering file organization stores related records of two or more relations in each block. The cluster key is the attribute that defines which records are stored together.
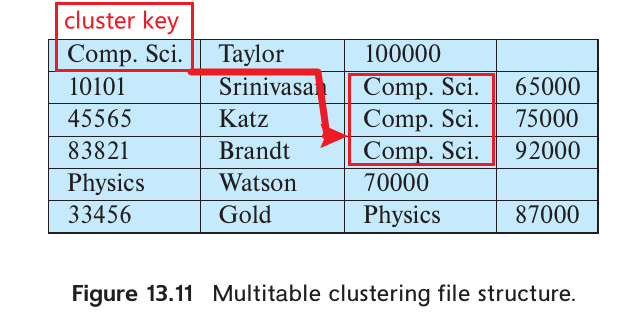
A multitable clustering file organization can speed up certain join queries but may slow down other types of queries.
The Oracle database system supports multitable clustering. Clusters are created using a create cluster command with a specified cluster key. The create table command extension can specify that a relation is stored in a specific cluster, using a particular attribute as the cluster key, allowing multiple relations to be allocated to one cluster.
B+-tree file organization
B+-tree file organization allows efficient ordered access even with numerous insertions, deletions, or updates while also enabling very efficient access to specific records based on the search key.
Detailed information will be discussed in #14.
Hasing file organization
A hash function is calculated based on a specific attribute of each record, determining the block in which the record should be stored in the file.
Detailed information will be discussed in #14.
Partitioning
Many databases allow records in a relation to be partitioned into smaller relations stored separately. Table partitioning is usually based on an attribute value, such as partitioning transaction records by year into separate relations for each year (e.g., transaction 2018, transaction 2019).
Table partitioning can avoid querying records with mismatched attributes. For example, a query select * from transaction where year=2019 would only access the relation transaction_2019.
Partitioning can help reduce costs for operations like finding free space for a record, as the size of relations increases. It can also be used to store different parts of a relation on separate storage devices. For example, in 2019, older transactions could be stored on magnetic disk while newer ones are stored on SSD for faster access.
#14 Indexing
Write-Optimized Index Structures
LSM Trees
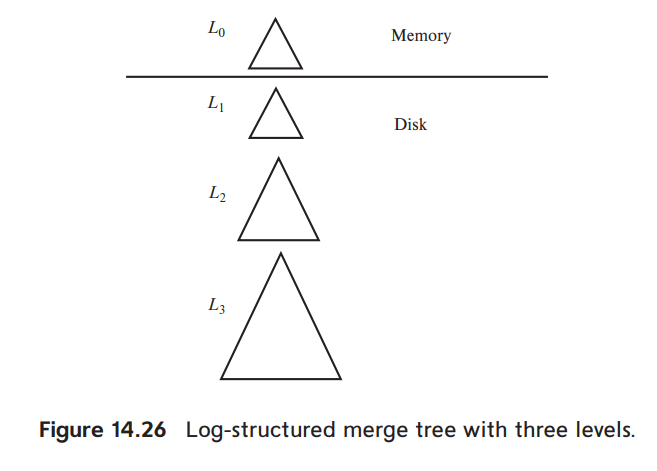
An LSM tree consists of several B+-trees (While it may not be a B+-tree like LevelDB, it is simply an ordered data structure), starting with an in memory tree, called L0 and on-disk L1, L2, …, Lk, where k is called the level.
Lookup operation is performed by merging all lookup operations on each of the tree.
When a certain level is filled, it will be copied and form a new tree to be placed in the next level.
Each level except L0 could have multiple B+-trees, which is called stepped-merge index. The stepped-merge index decreases the insert cost significantly compared to having only one tree per level, but it can result in an increase in query cost.
Deletion results in insertion of a new delete entry that indicated which index entry is to be deleted. If a deletion entry is found, the to-be-deleted entry is filtered out and not returned as part of the lookup result.
When trees are merged, if one of the trees contains an entry, and the other had a matching deletion entry, the entries get matched up during the merge (both would have the same key), and are both discarded. Updates follow a similar procedure, only the newest entry will be returned as lookup result and kept during the merge.
LSM trees were originally created to decrease the write and seek overheads of magnetic disks. Flash-based SSDs have a lower overhead for random I/O operations because they do not need seeking, so the advantage of avoiding random I/O that LSM tree variations offer is not as crucial with SSDs.
However, the flash memory does not allow in-place update, writing even a single byte to a disk page requires the whole page to be rewritten to a new physical location (The original location of the page needs to be erased firstly). Using LSM tree variants could reduce the number of writes and decrease the wearing rate.
Many BigData storage systems, including Apache Cassandra, Apache AsterixDB, and MongoDB, now support LSM trees. MySQL (with the MyRocks storage engine), SQLite4, and LevelDB also offer support for LSM trees.
#24 Advanced Indexing Techniques
Log-Structured Merge Tree and Variants
Insertion into LSM Trees
entt Documentation
介绍
本项目最初是一个 ECS 系统。随着时间推移,越来越多的类和功能被不断加入,代码库也随之持续扩展。
以下是它目前所提供功能的简要(且不完整)列表:
- 内置 RTTI 系统,与标准系统大体相似。
- 用于人类可读资源名称的 constexpr 工具。
- 基于单态模式构建的最小化配置系统。
- 极速的实体-组件系统,秉持“按需付费“原则,支持不受约束的组件类型,可选指针稳定性,以及用于存储自定义的钩子机制。
- 视图与分组,用于迭代实体和组件,支持从完美 SoA 到完全随机的多种访问模式。
- 大量构建于实体-组件系统之上的实用工具,助力用户开发,避免重复造轮子。
- 通用执行图构建器,用于最优调度。
- 有史以来最小、最基础的服务定位器实现。
- 内置的、非侵入式且无宏的运行时反射系统。
- 化繁为简的静态多态,人人触手可及。
- 若干自制容器,例如基于稀疏集的哈希映射。
- 用于任意类型进程的协作式调度器。
- 资源管理所需的一切(缓存、加载器、句柄)。
- 委托、信号处理器与轻量级事件分发器。
- 基于 CRTP 惯用法的通用事件发射器类模板。
- 以及更多内容!请查阅 wiki。
请将此列表与本项目一同视为持续演进的成果。所有 API 均已在代码中完整记录,供有胆识阅读的人参考。
另请注意,目前所有工具均已对 DLL 友好,并可在边界间平滑运行。
众所周知,EnTT 也被应用于《我的世界》(Minecraft)。鉴于该游戏几乎无处不在,我可以自信地说,这个库已经在所有能想到的平台上经过了充分测试。
Code Example
#include <cmath>
#include <iostream>
auto magnitude(auto const x, auto const y, auto const z) -> double {
return std::sqrt(x * x + y * y + z * z);
}
auto main() -> int {
auto const x = 2.;
auto const y = 3.;
auto const z = 5.;
std::cout << "The magnitude of the vector is "
<< magnitude(x, y, z)
<< "units.\n";
return 0;
}
#include <entt/entt.hpp>
struct position {
float x;
float y;
};
struct velocity {
float dx;
float dy;
};
void update(entt::registry ®istry) {
auto view = registry.view<const position, velocity>();
// use a callback
view.each([](const auto &pos, auto &vel) { /* ... */ });
// use an extended callback
view.each([](const auto entity, const auto &pos, auto &vel) { /* ... */ });
// use a range-for
for(auto [entity, pos, vel]: view.each()) {
// ...
}
// use forward iterators and get only the components of interest
for(auto entity: view) {
auto &vel = view.get<velocity>(entity);
// ...
}
}
int main() {
entt::registry registry;
for(auto i = 0u; i < 10u; ++i) {
const auto entity = registry.create();
registry.emplace<position>(entity, i * 1.f, i * 1.f);
if(i % 2 == 0) { registry.emplace<velocity>(entity, i * .1f, i * .1f); }
}
update(registry);
}
核心功能
目录
简介
EnTT 附带了一系列核心功能,主要供库的其他部分使用。
其中许多工具在日常开发中同样实用。因此,有必要对其进行说明,以免在需要时重复造轮子。
Any 即任意类型
EnTT 提供了自己的 any 类型。考虑到 C++17 已引入 std::any,这看似多余,但实际上并非如此。
首先,std::any 返回的 type 是 std::type_info 的 const 引用,这是一个实现定义的类,并非所有软件都希望在代码中看到它。此外,无法将其与库的类型系统及其集成的 RTTI 支持绑定。
any 的 API 与其著名的标准库对应物非常相似,主要是因为该类具有相同的目的:作为任意类型值的不透明容器。
实例还依赖于一种称为 小缓冲区优化 (small buffer optimization) 的知名技术和伪造的 vtable 来最小化内存分配次数。
创建 any 类型的对象(无论是否为空)非常简单:
// 空容器
entt::any empty{};
// 包含 int 的容器
entt::any any{0};
// 就地类型构造
entt::any in_place_type{std::in_place_type<int>, 42};
// 接管已存在的、动态分配的对象的拥有权
entt::any in_place{std::in_place, std::make_unique<int>(42).release()};
或者,make_any 函数可实现相同目的。它要求始终显式指定类型,且不支持接管所有权:
entt::any any = entt::make_any<int>(42);
在所有情况下,any 类都负责在需要时销毁包含的元素,而不管特定对象使用的存储策略如何。
此外,any 实例不绑定于实际类型。因此,当为其分配一个与其包含的类型不同的新对象时,包装器会重新配置。
还有一种方法可以直接为 entt::any 包含的变量赋值,而不必替换它。当对象在 别名模式 (aliasing mode) 下使用时,这特别有用,如下所述:
entt::any any{42};
entt::any value{3};
// 按拷贝赋值
any.assign(value);
// 按移动赋值
any.assign(std::move(value));
any 类会检查类型信息,并根据情况检查原始类型是否支持拷贝或移动赋值。
在所有情况下,assign 函数都会返回一个布尔值,成功时为 true,否则为 false。
如果对包含的对象类型有疑问,type 成员函数会返回与其元素关联的 type_info 的 const 引用;如果容器为空,则返回 type_id<void>()。
在比较两个 any 对象时,内部也会使用该类型:
if(any == empty) { /* ... */ }
在这种情况下,在进行比较之前,会验证两个对象的 type 是否确实相同。
有关 type_info 的工作原理及比较的潜在风险的更多详细信息,请参阅 EnTT 类型系统文档。
该类的一个特别有趣的功能是,它还可以用作 const 和非 const 引用的不透明容器:
int value = 42;
entt::any any{std::in_place_type<int &>(value)};
entt::any cany = entt::make_any<const int &>(value);
entt::any fwd = entt::forward_as_any(value);
any.emplace<const int &>(value);
换句话说,只要明确指示 any 构造 别名 (alias),它就会充当指向原始实例的指针,而不是在内部进行复制或移动。包含的对象永远不会被销毁,用户必须确保其生命周期长于容器。
同样,可以从现有对象创建 any 的非拥有拷贝 (non-owning copies):
// 别名构造函数
entt::any ref = other.as_ref();
在这种情况下,原始容器是实际持有对象,还是已经作为未托管元素的引用,都无关紧要。这样创建的新实例不会创建副本,仅作为原始项目的引用。
值得一提的是,虽然对于非 const 引用一切都能透明地工作,但对于 const 引用则存在一些例外。
特别是,在包装了 const 引用的 any 的非 const 实例上调用 data 成员函数时,在任何情况下都会返回空指针。
要将 any 实例转换为特定类型,库提供了一组 any_cast 函数,在各方面都与其著名的标准库对应物相似。
唯一的区别是,在 EnTT 中,它们不会抛出异常,而只会在 debug 模式下触发 assert,否则在 release 模式下误用会导致未定义行为。
小缓冲区优化
any 类使用一种称为 小缓冲区优化 (small buffer optimization) 的技术来尽可能减少内存分配次数。
any 实例的默认保留大小为 sizeof(double[2])。但是,如果需要,这也是可配置的。事实上,any 被定义为 basic_any<Len> 的别名,其中 Len 即为上述大小。
用户可以轻松设置自定义大小或定义自己的别名:
using my_any = entt::basic_any<sizeof(double[4])>;
此功能除了允许选择最适合应用程序需求的大小外,还提供了在构造期间强制动态创建对象的可能性。
换言之,如果大小为 0,any 将禁用小缓冲区优化,并始终动态分配对象(别名情况除外)。
对齐要求
对齐要求是可选的,默认情况下,对于大小不超过所提供大小的任何对象,采用最严格(最大)的对齐要求。
它作为可选的第二个参数提供,紧跟在内部存储的所需大小之后:
using my_any = entt::basic_any<sizeof(double[4]), alignof(double[4])>;
basic_any 类模板会在每种情况下检查对齐要求(即使未提供),并可能决定不使用小缓冲区优化以满足这些要求。
位运算
一些通用工具,例如快速取模函数:
const std::size_t result = entt::fast_mod(value, modulus);
其中 modulus 必须是 2 的幂。此类操作在性能上远优于基本取模运算,因此在许多领域更受青睐。
压缩 pair
compressed_pair 类主要为内部使用而设计,且远非功能完备,它完全兑现了其承诺:通过利用 空基类优化 (Empty Base Class Optimization, EBCO) 来尝试减小 pair 的大小。
此类 不是 std::pair 的无缝替代品 (drop-in replacement)。但是,当减少内存使用比拥有一些炫酷但可能无用的功能更重要时,它提供了足够的功能,是一个很好的替代方案。
尽管其 API 与 std::pair 非常接近(除了模板参数是从构造函数推导的,因此没有 entt::make_compressed_pair),但主要区别在于,出于实现要求,first 和 second 是函数:
entt::compressed_pair pair{0, 3.};
pair.first() = 42;
因此没有太多需要描述的。建议依赖文档和直觉。归根结底,它只是一个 pair,仅此而已。
枚举作为位掩码
有时将枚举用作位掩码 (bitmask) 很有用。然而,enum class 并不真正适合此目的。主要问题是它们不会隐式转换为其底层类型。
因此,选择在于使用老式枚举(带有我不想在此讨论的所有问题)或编写 丑陋 的代码。
幸运的是,还有第三种方法:在全局作用域中添加足够的运算符,以透明地将 enum class 视为位掩码。
最终目标是编写如下代码(或者可能是更有意义的代码,但这应该能让人领会且同时保持简单):
enum class my_flag {
unknown = 0x01,
enabled = 0x02,
disabled = 0x04
};
const my_flag flags = my_flag::enabled;
const bool is_enabled = !!(flags & my_flag::enabled);
将所有运算符添加到全局作用域的问题在于,即使不需要时它们也会生效,从而带来引入难以处理的错误的风险。
然而,C++ 提供了足够的工具来规避此问题。特别是,库要求用户注册应启用位掩码支持的 enum class:
template<>
struct entt::enum_as_bitmask<my_flag>
: std::true_type
{};
在处理由第三方库定义且用户无法控制的 enum class 时,这很方便。然而,这也很冗长,可以通过向 enum class 本身添加特定值来避免:
enum class my_flag {
unknown = 0x01,
enabled = 0x02,
disabled = 0x04,
_entt_enum_as_bitmask
};
在这种情况下,无需特化 enum_as_bitmask trait,因为 EnTT 会自动检测该标志并启用位掩码支持。
一旦注册了 enum class(通过某种方式),最常用的运算符(如 &、| 以及 &= 和 |=)就可供使用。
有关运算符的完整列表,请参阅官方文档。
哈希字符串
哈希字符串 (hashed strings) 是代码库中人类可读的标识符,它们在运行时转换为数值,因此不会影响性能。
该类具有一个隐式的 constexpr 构造函数,可解析一串字符。创建后,可以通过 data 成员函数获取原始字符串,或将实例转换为数字。
哈希字符串非常适合需要常量表达式的任何地方。如果谨慎使用,运行时不会发生 字符串到数字 的转换。
使用示例:
auto load(entt::hashed_string::hash_type resource) {
// 使用资源的数值表示来加载并返回它
}
auto resource = load(entt::hashed_string{"gui/background"});
还有一个专用于哈希字符串的 用户定义字面量 (user defined literal),使其更具 用户友好性:
using namespace entt::literals;
constexpr auto str = "text"_hs;
EnTT 中的用户定义字面量包含在 entt::literals 命名空间中。因此,在每次使用前,必须显式包含整个命名空间或选择性地包含感兴趣的字面量,这有点像 std::literals。
该类还提供了在运行时创建哈希字符串的必要功能:
std::string orig{"text"};
// 创建功能完整的哈希字符串...
entt::hashed_string str{orig.c_str()};
// ... 或仅计算唯一标识符
const auto hash = entt::hashed_string::value(orig.c_str());
不应在紧密循环 (tight loops) 中利用此可能性,因为计算发生在运行时而不是编译时。因此,它可能会在一定程度上影响性能。
宽字符
hashed_string 类是 basic_hashed_string<char> 的别名。要使用 C++ 类型进行宽字符表示,还存在 basic_hashed_string<wchar_t> 的别名 hashed_wstring。
在这种情况下,用于即时创建哈希字符串的用户定义字面量是 _hws:
constexpr auto str = L"text"_hws;
hashed_wstring 的哈希类型与其对应物相同。
冲突
哈希字符串类内部使用 FNV-1a 对字符串进行哈希处理。由于 鸽巢原理 (pigeonhole principle),冲突是可能的。这是一个事实。
在处理哈希函数时,没有解决冲突问题的银弹 (silver bullet)。在这种情况下,最好的解决方案可能是放弃。仅此而已。
毕竟,人类可读的唯一标识符并非严格定义,用户也无法完全控制。在这种情况下,选择一个略有不同的标识符可能是使冲突消失的最佳解决方案。
迭代器
编写和使用迭代器并不总是那么容易。通常它还会导致代码重复。
EnTT 试图通过提供一些旨在简化这项艰苦工作的工具来克服这个问题。
输入迭代器指针
在编写解引用时返回就地构造 (in-place constructed) 值的输入迭代器时,弄清楚 value_type 是什么以及如何使其表现得像一个成熟的指针并不总是那么直接。
相反,在迭代器本身上提供一个始终有效且没有太多复杂性的 operator-> 将非常有用。
输入迭代器指针正是为此而设计的。它是一个小型类,包装就地构造的值,并在其上添加一些函数,使其适合与输入迭代器一起使用:
struct iterator_type {
using value_type = std::pair<first_type, second_type>;
using pointer = input_iterator_pointer<value_type>;
using reference = value_type;
using difference_type = std::ptrdiff_t;
using iterator_category = std::input_iterator_tag;
// ...
}
库在内部广泛使用此类。在许多情况下,返回的迭代器的 value_type 只是一个输入迭代器指针。
Iota 迭代器
在等待 C++20 期间,此迭代器接受一个整数值并返回特定范围内的所有元素:
entt::iota_iterator first{0};
entt::iota_iterator last{100};
for(; first != last; ++first) {
int value = *first;
// ...
}
未来,views 将取代此类。同时,当需要向用户返回一系列整数值时,库会对其进行一些有趣的利用。
可迭代适配器
通常,容器类提供 begin 和 end 成员函数(及其 const 对应物)用于迭代。
但是,一个类可能会提供多种迭代方法,或允许用户迭代不同的 元素 (elements) 集合。
可迭代适配器 (iterable adaptor) 是一个工具类,在这种情况下可简化数据的使用和访问。
它接受一对迭代器(或一个迭代器和一个哨兵 (sentinel)),并提供一个具有所有预期方法(如 begin、end 等)的 可迭代 (iterable) 对象。
库广泛使用此类。
例如,考虑 views,可以对其进行迭代以访问实体,同时也提供一种方法来获取一个可迭代对象,该对象一次性返回实体和组件的 tuple。
另一个例子是 registry 类,它允许用户通过返回用于此目的的可迭代对象来迭代其存储。
内存
EnTT 中有一些工具可以以某种方式与内存交互。
其中一些旨在简化(内部或外部)分配器感知 (allocator aware) 容器的实现。另一些旨在帮助开发者解决日常问题。
前者非常具体,针对小众问题。例如,有些工具旨在帮助人们忘记 POCCA、POCMA 或 POCS 等首字母缩略词的含义。
我不会在这里详细描述它们。相反,我建议对该主题感兴趣的人阅读内联文档。
分配器感知 unique pointer
C++ 中(至少到 C++20 为止)一件棘手的事情是,shared pointer 支持分配器,而 unique pointer 却不支持。
目前有一个提案也展示了(除其他外)如何在没有任何编译器支持的情况下实现这一点。
allocate_unique 函数遵循此提案,化被动为主动:
std::unique_ptr<my_type, entt::allocation_deleter<allocator_type>> ptr = entt::allocate_unique<my_type>(allocator, arguments);
尽管内部实现与标准提案略有不同,但此函数提供的 API 是该特性的无缝替代品 (drop-in replacement)。
单态模式
单态 (monostate) 模式通常被作为基于单例 (singleton) 的配置系统的替代方案提出。
这正是它在 EnTT 中的目的。此外,此实现在设计上是线程安全的(希望如此)。
键是整数值(可通过哈希字符串轻松获取),值是 int 或 bool 等基本类型。不同类型的值可以与每个键关联,甚至可以一次关联多个。
因此,在赋值和尝试读回数据时,应注意使用相同的类型。否则,有可能会出现意外结果。
使用示例:
entt::monostate<entt::hashed_string{"mykey"}>{} = true;
entt::monostate<"mykey"_hs>{} = 42;
// ...
const bool b = entt::monostate<"mykey"_hs>{};
const int i = entt::monostate<entt::hashed_string{"mykey"}>{};
类型支持
EnTT 提供各种类型的一些基本信息。
它还提供标准库中尚未提供或永远不会提供的附加功能。
内置 RTTI 支持
运行时类型识别 (RTTI) 支持是 C++ 世界中最常被禁用的功能之一,尤其是在游戏领域。无论原因如何,在运行时无法依赖不透明的类型信息通常是一件憾事。
库试图通过提供一个内置系统来填补这一空白,该系统虽然不能作为替代品,但非常接近,并提供与其对应物类似的信息。
基本上,整个系统依赖于少数几个类。特别是:
-
与给定类型关联的唯一顺序标识符:
auto index = entt::type_index<a_type>::value();不保证返回值在不同的运行中保持稳定。
然而,它作为关联和无序关联容器中的索引,或用于 vector 或 array 中的位置访问,非常有用。如果需要,也可以使用外部生成器。事实上,
type_index可以按类型特化,或使用 concept 进行约束,以允许更精细的特化,例如:template<typename Type> requires requires { { Type::index() } -> std::same_as<entt::id_type>; } struct entt::type_index<Type> { static entt::id_type value() noexcept { return Type::index(); } };在这种情况下,索引 必须 按顺序生成。
该工具在EnTT中被广泛使用。非顺序生成索引会破坏一个假设,并可能导致不良行为。 -
与给定类型关联的哈希值:
auto hash = entt::type_hash<a_type>::value();通常,
type_hash公开的value函数也是constexpr的,但这并不能保证适用于所有编译器和平台(尽管它对最知名和最流行的编译器有效)。此函数 可以 为其自身目的使用语言的非标准特性。这使得提供在不同运行中保持稳定的编译时标识符成为可能。
用户可以通过ENTT_STANDARD_CPP宏定义阻止库使用这些特性。在这种情况下,无法保证标识符在多次执行中保持稳定。此外,它们是在运行时生成的,不再是编译时的东西。与
type_index一样,type_hash也可以特化或使用 concept 约束,以便全局或按类型/按 trait 自定义其行为。 -
与给定类型关联的名称:
auto name = entt::type_name<a_type>::value();此值提取自所用编译器通常提供的一些信息。因此,它可能因编译器而异,并且在信息不可用时可能为空。
例如,给定以下类:struct my_type { /* ... */ };使用 GCC 或 CLang 编译时名称为
my_type,使用 MSVC 时为struct my_type。
大多数时候,名称也是在编译时检索的,因此始终通过std::string_view返回。用户可以轻松访问并根据需要修改它,例如删除struct一词以标准化结果。出于显而易见的原因,EnTT不会这样做,否则它将在运行时创建一个新字符串。此函数 可以 为其自身目的使用语言的非标准特性。用户可以通过
ENTT_STANDARD_CPP宏定义阻止库使用这些特性。在这种情况下,名称只是为空。与
type_index一样,type_name也可以特化或使用 concept 约束,以便全局或按类型/按 trait 自定义其行为。
然后将这些组合成工具,旨在提供与标准库提供的 API 有些相似的 API。
类型信息
type_info 类不是 std::type_info 的无缝替代品 (drop-in replacement),但可以提供类似的信息,这些信息不是实现定义的,也不需要启用 RTTI。
因此,它们有时甚至比通过其他方式获得的信息更可靠。
其类型定义了一个不透明的类,该类也是可拷贝和可移动的。
此类型的对象通常由 type_id 函数返回:
// 按类型
auto info = entt::type_id<a_type>();
// 按值
auto other = entt::type_id(42);
这样接收到的所有元素不过是具有静态存储期的 type_info 实例的 const 引用。
这便于保存整个对象,而只需付出一个指针的代价。然而,没有什么能阻止直接构造 type_info 对象:
entt::type_info info{std::in_place_type<int>};
以下是 type_info 提供的信息:
-
与给定类型关联的索引:
auto idx = entt::type_id<a_type>().index();这也是以下代码的别名:
auto idx = entt::type_index<std::remove_cvref_t<a_type>>::value(); -
与给定类型关联的哈希值:
auto hash = entt::type_id<a_type>().hash();这也是以下代码的别名:
auto hash = entt::type_hash<std::remove_cvref_t<a_type>>::value(); -
与给定类型关联的名称:
auto name = entt::type_id<my_type>().name();这也是以下代码的别名:
auto name = entt::type_name<std::remove_cvref_t<a_type>>::value();
如果所有访问的特性在编译时都可用,则 type_info 类也是完全 constexpr 的。然而,这无法提前保证,主要取决于所使用的编译器以及上述类的任何特化。
近乎唯一的标识符
由于 type_hash 的默认非标准编译时实现利用了哈希字符串,因此可能会发生两个类型被分配相同哈希值的情况。
事实上,虽然这种情况非常罕见,但并未完全排除。
另一种两个类型被分配相同标识符的情况是,来自不同上下文(例如在运行时加载的两个或多个库)的类具有相同的全限定名。在这种情况下,type_name 为这两个类型返回相同的值。
幸运的是,有几种简单的方法可以处理这个问题:
-
最简单的方法是定义
ENTT_STANDARD_CPP宏。事实上,运行时标识符不会遇到同样的问题。然而,此解决方案在库未链接的插件系统中效果不佳。 -
另一种可能性是为冲突的类型之一特化
type_name类,以便为其分配自定义标识符。这可能是最简单的解决方案,同时也保留了该工具的特性。 -
完全自定义的标识符生成策略(例如基于 enum class 或预处理步骤)可能代表另一种选择。
这些只是解决该问题的可能方法的一些示例,但还有许多其他方法。如上所述,由于用户对其类型拥有完全控制权,因此无论如何这个问题都很容易解决,不必过于担心。
无论如何,极大概率不会遇到冲突。
类型萃取
标准模板库中不存在但在日常生活中可能有用的一些工具和类型萃取 (type traits)。
此列表 并非 详尽无遗,仅包含一些最有用的类。有关此模块提供功能的更多信息,请参阅内联文档。
Size of
如果用户向标准运算符 sizeof 提供函数或不完整类型,它会报错。另一方面,即使应用于空类类型,也保证结果始终为非零。
这个小型类结合了两者,并提供了一种在所有情况下都有效的 sizeof 替代方案,如果类型不受支持则返回零:
const auto size = entt::size_of_v<void>;
Is applicable
标准库以多种形式提供了出色的 std::is_invocable trait。它接受一个函数类型和一系列参数,如果满足条件则返回 true。
此外,还为用户提供了 std::apply,这是一个用于组合可调用元素和参数 tuple 的工具。
因此,拥有一个也接受 tuple-like 类型参数的 std::is_invocable 变体以完善功能是个好主意:
constexpr bool result = entt::is_applicable<Func, std::tuple<a_type, another_type>>;
此 trait 构建在 std::is_invocable 之上,除了展开 tuple-like 类型并简化调用点代码外,别无他用。
Constness as
一个轻松将类型的 const 属性 (constness) 转移到另一种类型的工具:
// 由于 src_type 的 const 属性,type 为 const dst_type
using type = entt::constness_as_t<dst_type, const src_type>;
该 trait 受语言规则的约束。例如,在引用之间 转移 const 属性不会产生预期的效果。
成员类类型
C++17 引入的 auto 模板参数使得简化许多类模板和模板函数成为可能,但当成员作为模板参数传递时,也使得类类型变得不透明。
此工具的目的是在几行代码中提取类类型:
template<typename Member>
using clazz = entt::member_class_t<Member>;
第 N 个参数
一个快速查找函数、成员函数或数据成员的第 n 个参数的工具(用于对不透明类型的盲操作):
using type = entt::nth_argument_t<1u, decltype(&clazz::member)>;
如果需要,重载函数的消歧由用户负责。
整型常量
由于 std::integral_constant 的形式要求同时指定类型和该类型的值,可能有些烦人,因此存在一个更用户友好的快捷方式来创建整型常量 (integral constants)。
此快捷方式是别名模板 entt::integral_constant:
constexpr auto constant = entt::integral_constant<42>;
在其他用途中,当与哈希字符串结合使用时,它有助于将标签 (tags) 定义为人类可读的 名称,否则将需要实际的类型:
constexpr auto enemy_tag = entt::integral_constant<"enemy"_hs>;
registry.emplace<enemy_tag>(entity);
标签
id_type 类型在 EnTT 中非常重要且被广泛使用。因此,存在一个更用户友好的快捷方式来基于它创建常量。
此快捷方式是别名模板 entt::tag。
如果与哈希字符串结合使用,它有助于在需要类型的地方使用人类可读的名称。例如:
registry.emplace<entt::tag<"enemy"_hs>>(entity);
然而,这不是唯一允许的用法。实际上,任何可转换为 id_type 的值都是很好的候选者,例如无作用域枚举 (unscoped enum) 的命名常量。
类型列表与值列表
没有任何受人尊敬的库会缺少急需的 类型列表 (type list)。
EnTT 也不例外,除了提供专用于非类型模板参数的 value_list 对应物外,还提供了(并在内部广泛使用)type_list 类型。
以下是类型列表附带功能的(可能不完整的)列表:
type_list_element[_t]获取类型列表的第 N 个元素。type_list_index[_v]获取类型列表给定元素的索引。type_list_cat[_t]和便捷的operator+用于连接类型列表。type_list_unique[_t]从类型列表中移除重复类型。type_list_contains[_v]了解类型列表是否包含给定类型。type_list_diff[_t]从类型列表中移除类型。type_list_transform[_t]转换 (transform) 范围并创建另一个类型列表。
我也非常确定,随着需求变得明显,随着时间的推移会添加越来越多的工具。
许多这些功能也存在于专用于值列表 (value lists) 的版本中。因此我们有 value_list_element[_v] 以及 value_list_cat[_t] 等等。
唯一顺序标识符
有时,能够在编译时或运行时为类型赋予唯一的、顺序的数字标识符是有用的。
针对此问题有许多不同的解决方案,我本可以使用其中之一。然而,我决定花时间定义几个完全拥抱现代 C++ 所提供特性的工具。
编译时生成器
为了在编译时生成顺序数字标识符,EnTT 提供了 ident 类模板:
// 为给定类型定义标识符
using id = entt::ident<a_type, another_type>;
// ...
switch(a_type_identifier) {
case id::value<a_type>:
// ...
break;
case id::value<another_type>:
// ...
break;
default:
// ...
}
这就是此类模板提供的全部:一个包含给定类型的数字标识符的 value 内联变量。它可以在任何需要常量表达式的上下文中使用。
只要列表保持不变,标识符也保证在不同的运行中保持稳定。如果在需要移除某个类型的生产环境中使用,占位符 (placeholder) 可以帮助保持其他标识符不变:
template<typename>
struct ignore_type {};
using id = entt::ident<
a_type_still_valid,
ignore_type<no_longer_valid_type>,
another_type_still_valid
>;
在代码库中看起来可能有点丑陋,但至少能完成任务。
运行时生成器
family 类模板有助于在运行时为类型生成顺序数字标识符:
// 定义自定义生成器
using id = entt::family<struct my_tag>;
// ...
const auto a_type_id = id::value<a_type>;
const auto another_type_id = id::value<another_type>;
这就是 family 提供的全部:一个包含给定类型的数字标识符的 value 内联变量。
生成器是可定制的,以便在需要时为不同目的获取不同的 序列 (sequences)。
不保证标识符在不同的运行中保持稳定。事实上,它主要取决于执行流程。
实用工具
无法抗拒向库中添加某种工具的诱惑。事实上,EnTT 还提供了一些工具来简化开发者的生活:
-
entt::overload:一个用于根据其函数类型消除不同重载歧义的工具。它适用于自由函数和成员函数。
考虑以下定义:struct clazz { void bar(int) {} void bar() {} };此工具可用于获取 正确 的重载,如下所示:
auto *member = entt::overload<void(int)>(&clazz::bar);上面这行代码在字面上等价于:
auto *member = static_cast<void(clazz:: *)(int)>(&clazz::bar);只是更易读且输入更短。
-
entt::overloaded:一个小型类模板,用于从一堆 lambda 或 functor 创建一个具有重载operator()的新类型。
例如:entt::overloaded func{ [](int value) { /* ... */ }, [](char value) { /* ... */ } }; func(42); func('c');在进行元编程并必须向函数传递同时支持多种类型的可调用对象时相当有用。
-
entt::y_combinator:这是 Y 组合子 (y-combinator) 的 C++ 实现。如果不清楚它是什么,可能就不需要这个工具。
下面是一个展示其用法的小示例:entt::y_combinator gauss([](const auto &self, auto value) -> unsigned int { return value ? (value + self(value-1u)) : 0; }); const auto result = gauss(3u);乍一看可能有些复杂,但确实有效。不幸的是,该语言无法使其做得更好。
这是 EnTT 提供的(实际上很少的)工具的简要概述。随着时间的推移,这个列表可能会增长,但每个工具的规模将保持相当小,正如迄今为止的情况一样。
实体-组件-系统 (ECS)
目录
- 实体-组件-系统 (ECS)
- 目录
- 简介
- 设计决策
- 使用须知 (Vademecum)
- Registry、Entity 与 Component
- Storage
- 运行时的邂逅
- Views 与 Groups
- 多线程
- 文档之外
简介
EnTT 提供了一个仅头文件 (header-only)、小巧且易于使用的 entity-component system (ECS) 模块,采用现代 C++ 编写。
实体-组件-系统(Entity-Component-System,简称 ECS)是一种主要用于游戏开发的架构模式。
设计决策
无类型且无 bitset
本库实现了一种基于稀疏集 (sparse set) 的模型,不需要用户在编译时或运行时指定组件集合。
这就是为什么用户可以简单地实例化核心类:
entt::registry registry;
而不是其更烦人且容易出错的对应物:
entt::registry<comp_0, comp_1, ..., comp_n> registry;
此外,没有必要提前声明组件类型的存在。当需要使用时,直接使用即可。
自行构建
ECS 模块(以及库的其余部分)被设计为一组按需使用的容器,就像 vector 或任何其他容器一样。它绝不试图接管用户的代码库,也不控制其主循环或进程调度。
与其他或多或少知名的模型不同,它还利用通过 静态 mixin (static mixins) 扩展的独立池 (independent pools)。内置的信号 (signal) 支持就是这种灵活设计的一个例子:它被定义为一个 mixin,如果不需要可以轻松禁用。同样,storage 类也有一个特化版本,展示了如何将一切定制到最细微的细节。
按需付费
一切设计都围绕用户只需为他们想要的东西付费的原则。
在使用 ECS 时,权衡通常在性能和内存使用之间。速度越快,使用的内存就越多。更糟糕的是,一些方法倾向于严重影响其他功能(如组件的构造和销毁)以偏向迭代,即使并非严格需要。事实上,在非关键路径上牺牲一点性能,是减少内存使用并获得整体更好性能的正确代价。
EnTT 采用了完全不同的方法。它从基础数据结构中榨取最大价值,并让用户能够在需要时为更高性能付出更多代价。
全有或全无
根据经验,T ** 指针(或自定义池返回的任何内容)始终可用于直接访问给定组件类型 T 的所有实例。
这是本库的基石之一。提供的许多工具都是围绕这一需求设计的,并提供了获取此信息的可能性。
使用须知 (Vademecum)
entt::entity 类型实现了 实体标识符 (entity identifier) 的概念。实体(ECS 中的 E)是一个不透明的元素,应直接使用。不建议检查它,因为其格式在未来可能会改变。
组件(ECS 中的 C)可以是任何类型,没有任何限制,甚至不需要是可移动的 (movable)。无需注册它们或其类型。
系统(ECS 中的 S)是普通的函数、仿函数 (functors)、lambda 等。在任何情况下都不需要声明它们,也没有任何要求。
接下来的部分将详细介绍如何使用 EnTT 库的 entity-component system 部分。
该模块可能比下面描述的更大。有关更多详细信息,请参阅内联文档。
Registry、Entity 与 Component
Registry 存储并管理实体(或 标识符)和组件。
类模板 basic_registry 让用户决定表示实体的首选类型。因为 std::uint32_t 对几乎所有情况都足够大,所以还存在 包装 它的 enum class entt::entity 以及 entt::basic_registry<entt::entity> 的别名 entt::registry。
实体由 实体标识符 表示。实体标识符包含有关实体本身及其版本 (version) 的信息。
允许用户定义的标识符作为 enum class 和定义了 std::uint32_t 或 std::uint64_t 类型的 entity_type 成员的 class type。
Registry 既用于构造也用于销毁实体:
// 构造一个没有任何组件的裸实体并返回其标识符
auto entity = registry.create();
// 销毁一个实体及其所有组件
registry.destroy(entity);
create 成员函数还接受一个 hint。此外,它有一个重载,接收两个 iterator 以一次性高效生成多个实体。同样,destroy 成员函数也适用于实体范围:
// 销毁范围内的所有实体
auto view = registry.view<a_component, another_component>();
registry.destroy(view.begin(), view.end());
除了提供一个重载以在销毁时强制指定版本外。
此函数在释放实体之前会从中移除所有组件。还存在一种 更轻量 的替代方法,它不查询组件池,用于处理孤儿实体 (orphaned entities):
// 释放孤儿标识符
registry.release(entity);
与 destroy 函数一样,在这种情况下也支持实体范围,并且可以强制指定 version。
在这两种情况下,当标识符被释放时,registry 可以在内部自由地重用它。特别是,实体的版本会增加(除非使用强制指定版本的重载而不是默认重载)。
然后,用户可以通过 registry 测试 标识符:
// 如果实体仍然有效则返回 true,否则返回 false
bool b = registry.valid(entity);
// 获取给定实体的实际版本
auto curr = registry.current(entity);
或者使用一些旨在按原样解析标识符的函数来 检查 它们,例如:
// 获取实体标识符中包含的版本
auto version = entt::to_version(entity);
组件可以在任何时候分配给实体或从实体中移除。
emplace 成员函数模板创建、初始化给定的组件并将其分配给实体。它接受可变数量的参数用于构造组件本身:
registry.emplace<position>(entity, 0., 0.);
// ...
auto &vel = registry.emplace<velocity>(entity);
vel.dx = 0.;
vel.dy = 0.;
默认 storage 在内部 检测 聚合类型 (aggregate types) 并在可能时利用聚合初始化。
因此,并非严格需要为每种类型定义构造函数。
insert 成员函数适用于 范围 (ranges) 并用于:
-
当将类型指定为模板参数或将实例作为参数传递时,一次性将同一组件分配给所有实体:
// 默认初始化的类型通过拷贝分配给所有实体 registry.insert<position>(first, last); // 用户定义的实例通过拷贝分配给所有实体 registry.insert(from, to, position{0., 0.}); -
当提供范围时,将一组组件分配给实体(组件范围的长度 必须 与实体范围的长度相同):
// first 和 last 指定实体的范围,instances 指向组件范围的第一个元素 registry.insert<position>(first, last, instances);
如果实体已经拥有给定的组件,则使用 replace 和 patch 成员函数模板来更新它:
// 就地替换组件
registry.patch<position>(entity, [](auto &pos) { pos.x = pos.y = 0.; });
// 从参数列表构造一个新实例并替换组件
registry.replace<position>(entity, 0., 0.);
当不知道实体是否已经拥有组件实例时,应改用 emplace_or_replace 函数:
registry.emplace_or_replace<position>(entity, 0., 0.);
这是以下代码段的稍快替代方案:
if(registry.all_of<velocity>(entity)) {
registry.replace<velocity>(entity, 0., 0.);
} else {
registry.emplace<velocity>(entity, 0., 0.);
}
如果对实体是否拥有集合中的所有组件或其中任何一个组件有疑问,all_of 和 any_of 成员函数也可能很有用:
// 如果实体拥有所有给定的组件则为 true
bool all = registry.all_of<position, velocity>(entity);
// 如果实体至少拥有给定组件之一则为 true
bool any = registry.any_of<position, velocity>(entity);
如果目标是从拥有它的实体中删除组件,则使用 erase 成员函数模板:
registry.erase<position>(entity);
当不确定实体是否拥有该组件时,请改用 remove 成员函数。它的行为类似于 erase,但仅在组件存在时才删除它,否则安全地返回给调用者:
registry.remove<position>(entity);
clear 成员函数的行为类似,用于:
-
从拥有给定组件的实体中擦除它们的所有实例:
registry.clear<position>(); -
或一次性销毁 registry 中的所有实体:
registry.clear();
最后,获取组件的引用非常简单:
const auto &cregistry = registry;
// const 和非 const 引用
const auto &crenderable = cregistry.get<renderable>(entity);
auto &renderable = registry.get<renderable>(entity);
// const 和非 const 引用
const auto [cpos, cvel] = cregistry.get<position, velocity>(entity);
auto [pos, vel] = registry.get<position, velocity>(entity);
如果不确定组件是否存在,则 try_get 是更合适的函数。
观察变更
默认情况下,每个 storage 都带有一个 mixin,为其添加 signal 支持。
这允许实现诸如依赖关系和响应式系统 (reactive systems) 等高级功能。
on_construct 成员函数返回一个 sink(这是一个用于连接和断开 listener 的对象),供那些对在创建给定组件类型的新实例时收到通知感兴趣的人使用:
// 连接自由函数
registry.on_construct<position>().connect<&my_free_function>();
// 连接成员函数
registry.on_construct<position>().connect<&my_class::member>(instance);
// 断开自由函数
registry.on_construct<position>().disconnect<&my_free_function>();
// 断开成员函数
registry.on_construct<position>().disconnect<&my_class::member>(instance);
同样,on_destroy 和 on_update 分别用于接收有关实例销毁和更新的通知。
由于 C++ 的工作方式,附加到 on_update 的 listener 仅在调用 replace、emplace_or_replace 或 patch 后被调用。
通过向上述函数提供标识符,也支持运行时池 (runtime pools):
registry.on_construct<position>("other"_hs).connect<&my_free_function>();
有关运行时池的更多信息,请参阅以下部分。
在所有情况下,listener 的函数类型等同于以下内容:
void(entt::registry &, entt::entity);
所有 listener 都会收到触发通知的 registry 和涉及的实体。还要注意:
- 构造信号的 listener 在组件创建 之后 被调用。
- 旨在观察变更的 listener 在组件更新 之后 被调用。
- 销毁信号的 listener 在组件销毁 之前 被调用。
对 listener 可以做什么和不能做什么也有一些限制:
- 应避免在 listener 的函数体内连接和断开其他函数。在某些情况下,这可能会导致未定义行为。
- 不允许在观察给定类型实例构造或更新的 listener 的函数体内移除组件。
- 应避免在观察给定类型实例销毁的 listener 的函数体内分配和移除组件。在某些情况下,这可能会导致未定义行为。此类 listener 旨在为用户提供一种执行清理的简单方法,仅此而已。
请参阅 signal 类的文档以了解其提供的所有功能。
有许多有用但不太为人熟知的功能在此未描述,例如连接对象 (connection objects) 或使用比 signal 本身更短的参数列表附加 listener 的可能性。
自动绑定
用户无需每次都手动创建绑定。对于托管类型,他们可以让 EnTT 自动设置 listener。
库会在类型中搜索具有特定名称和签名的函数,如以下示例所示:
struct my_type {
static void on_construct(entt::registry ®istry, const entt::entity entt);
static void on_update(entt::registry ®istry, const entt::entity entt);
static void on_destroy(entt::registry ®istry, const entt::entity entt);
// ...
};
一旦为这种定义的类型创建了 storage,这些函数就会与各自的 signal 关联。函数名称不言自明地指示了目标 signal。
Entity 生命周期
也可以观察实体。在这种情况下,用户必须使用 entity 类型而不是 component 类型:
registry.on_construct<entt::entity>().connect<&my_listener>();
由于 entity storage 在 registry 中是唯一的,如果提供了 name,它将被忽略并因此被丢弃。
至于函数签名,这与组件完全相同。
实体支持所有类型的 signal:构造、销毁和更新。后者可能有些歧义,因为实体并未真正被 更新。相反,它的标识符被创建并最终被释放。
实际上,update signal 旨在发送有关实体的 一般通知。它可以像组件一样通过 patch 函数触发:
registry.patch<entt::entity>(entity);
销毁实体然后更新标识符的版本在任何情况下都 不会 引发这些类型的 signal。
最后,请注意,观察 实体销毁的 listener 会在所有组件被移除 之后 被调用,而不是 之前。这是因为否则在删除其元素之前实体会被失效,从而使用户难以编写组件 listener。
Listener 断开连接
storage 类的销毁顺序以及因此 listener 的断开连接是完全随机的。
目前没有任何保证,虽然逻辑很容易推断,但不能保证将来会保持如此。
例如,在由于池销毁而丢弃组件后断开连接的 listener 很可能是引发问题的根源。
相反,建议在销毁 registry 之前调用其 clear 函数。这会强制删除所有组件和实体,而永远不会丢弃池。
因此,想要访问组件、实体或池的 listener 可以安全地对仍然有效的 registry 执行此操作,同时适当地检查各个元素的存在。
响应式 Storage
Signal 是构建响应式系统 (reactive systems) 的基本工具,即使它们本身还不够。EnTT 试图通过其 响应式 mixin (reactive mixin) 朝着这个方向再迈出一步。
为了解释什么是响应式系统,这是首次引入此工具的库 Entitas 文档中稍作修改的引用:
想象一下,你在战场有 100 个战斗单位,但只有 10 个改变了位置。你可以使用响应式系统,它只更新这 10 个改变的单位,而不是使用普通系统并根据位置更新所有 100 个实体。如此高效。
在 EnTT 中,这意味着迭代一组比从 view 或 group 返回的实体和组件更小的集合。
然而,到此为止,与 Entitas 提案的相似之处也结束了。语言的规则和库的设计显然强加并允许了不同的事物。
响应式 mixin 可用于具有任何值类型的独立 storage(也许使用别名以简化其使用):
using reactive_storage = entt::reactive_mixin<entt::storage<void>>;
entt::registry registry{};
reactive_storage storage{};
storage.bind(registry);
在这种情况下,必须为其提供一个引用的 registry 以进行后续操作。
或者,当使用 EnTT 提供的值类型时,也可以直接在 registry 内创建响应式 storage:
entt::registry registry{};
auto &storage = registry.storage<entt::reactive>("observer"_hs);
在后一种情况下,优点是,如果实体被销毁,此 storage 也会被自动清理。
还要注意,与所有其他 storage 不同,这些类默认不支持 signal(尽管如果需要可以启用)。
一旦创建并与 registry 关联,响应式 mixin 需要被告知它应该 观察 什么。
这里的选择归结为影响所有元素(实体或组件)的三个主要事件,即创建、更新或销毁:
storage
// 观察 position 组件的构造
.on_construct<position>()
// 观察 velocity 组件的更新
.on_update<velocity>()
// 观察 renderable 组件的销毁
.on_destroy<renderable>();
不言而喻,可以使用同一个 storage 观察相同类型或不同类型的多个事件。
例如,要知道哪些实体被分配或更新了某种类型的组件:
storage
.on_construct<my_type>()
.on_update<my_type>();
请注意,所有配置都是 或 (or) 关系,绝不是 与 (and) 关系。因此,要跟踪被分配了两个不同组件的实体,有几个选项:
-
创建两个响应式 storage,然后将它们组合到一个 view 中:
first_storage.on_construct<position>(); second_storage.on_construct<velocity>(); for(auto entity: entt::basic_view{first_storage, second_storage}) { // ... } -
使用具有非
void值类型的响应式 storage 和用于此目的的自定义跟踪函数:using my_reactive_storage = entt::reactive_mixin<entt::storage<bool>>; void callback(my_reactive_storage &storage, const entt::registry &, const entt::entity entity) { storage.contains(entity) ? (storage.get(entity) = true) : storage.emplace(entity, false); } // ... my_reactive_storage storage{}; storage .on_construct<position, &callback>() .on_construct<velocity, &callback>(); // ... for(auto [entity, both_were_added]: storage.each()) { if(both_were_added) { // ... } }
正如最后一个示例所强调的,响应式 mixin 跟踪满足给定条件的实体并将它们保存在一旁。但是,可以更改此行为。
例如,可以 捕获 所有且仅当特定值在给定范围内时某个组件被更新的实体:
void callback(reactive_storage &storage, const entt::registry ®istry, const entt::entity entity) {
storage.remove(entity);
if(const auto x = registry.get<position>(entity).x; x >= min_x && x <= max_x) {
storage.emplace(entity);
}
}
// ...
storage.on_update<position, &callback>();
这使得响应式 storage 极其灵活,可用于大量情况。
最后,一旦收集了感兴趣的实体,就可以像任何其他 storage 一样 访问 它:
for(auto entity: storage) {
// ...
}
将其包装在 view 中并与其他 view 组合是另一种选择:
for(auto [entity, pos]: (entt::basic_view{storage} | registry.view<position>(entt::exclude<velocity>)).each()) {
// ...
}
为了简化最后一种用例,响应式 mixin 还提供了一个特定函数,该函数返回已根据提供的要求过滤的 storage 的 view:
for(auto [entity, pos]: storage.view<position>(entt::exclude<velocity>).each()) {
// ...
}
在这种情况下使用的 registry 是与 storage 关联的 registry,也可以通过 registry 函数获得。
应该注意的是,响应式 storage 永远不会删除其实体(以及元素,如果有的话)。要定期处理然后丢弃实体,请参阅默认情况下每种 storage 类型都可用的 clear 函数。
同样,响应式 mixin 在销毁时不会自行从观察的 storage 中断开连接。因此,用户必须自己执行此操作:
entt::registry = storage.registry();
registry.on_construct<position>().disconnect(&storage);
registry.on_construct<velocity>().disconnect(&storage);
如果不从观察的池中断开连接就销毁响应式 storage,将导致未定义行为。
排序:可行吗?
可以使用不需要内存分配的就地算法 (in-place algorithm) 对实体和组件进行排序,因此非常方便。
有两个函数响应略有不同的需求:
-
直接对组件进行排序:
registry.sort<renderable>([](const renderable &lhs, const renderable &rhs) { return lhs.z < rhs.z; });或者通过访问它们的实体:
registry.sort<renderable>([](const entt::entity lhs, const entt::entity rhs) { return entt::registry::entity(lhs) < entt::registry::entity(rhs); });当使用模式已知时,还可以使用自定义排序函数对象。
-
根据另一个组件施加的顺序对组件进行排序:
registry.sort<movement, physics>();在这种情况下,
movement的实例在内存中排列,以便在两个组件一起迭代时最小化缓存未命中 (cache misses)。
顺便提一下,group 的使用限制了组件池排序的可能性。有关更多详细信息,请参阅特定文档。
辅助工具 (Helpers)
所谓的 helpers 是主要设计用于为最基本的功能提供内置支持的小型类和函数。
Null Entity
entt::null 变量建模了 null entity 的概念。
库保证以下表达式始终返回 false:
registry.valid(entt::null);
Registry 在所有情况下都拒绝 null entity,因为它不被认为是有效的。这也意味着 null entity 不能拥有组件。
null entity 的类型是内部的,除了定义 null entity 本身之外,不应用于任何其他目的。但是,存在从 null entity 到任何允许类型的标识符的隐式转换:
entt::entity null = entt::null;
同样,null entity 可与任何其他标识符进行比较:
const auto entity = registry.create();
const bool null = (entity == entt::null);
至于其整数形式,null entity 仅影响标识符的 entity 部分,而对其 version 部分完全透明。
请注意,entt::null 和实体 0 是不同的。同样,零初始化的实体也不等同于 entt::null。因此,尽管 entt::entity{} 在某种意义上是实体 0 的别名,但它们都不用于创建 null entity。
Tombstone
与 null entity 类似,entt::tombstone 变量建模了 tombstone(墓碑)的概念。
一旦创建,这两个值的整数形式是相同的,尽管它们影响标识符的不同部分。事实上,tombstone 仅使用其 version 部分,而对 entity 部分完全透明。
同样在这种情况下,以下表达式始终返回 false:
registry.valid(entt::tombstone);
此外,用户在释放实体时不能设置 tombstone 版本:
registry.destroy(entity, entt::tombstone);
在这种情况下,会隐式生成一个不同的版本号。
tombstone 的类型是内部的,随时可能改变。但是,存在从 tombstone 到任何允许类型的标识符的隐式转换:
entt::entity null = entt::tombstone;
同样,tombstone 可与任何其他标识符进行比较:
const auto entity = registry.create();
const bool tombstone = (entity == entt::tombstone);
请注意,entt::tombstone 和实体 0 是不同的。同样,零初始化的实体也不等同于 entt::tombstone。因此,尽管 entt::entity{} 在某种意义上是实体 0 的别名,但它们都不用于创建 tombstone。
To entity
此函数接受一个 storage 和该 storage 类型的组件实例,然后返回与后者关联的实体:
const auto entity = entt::to_entity(registry.storage<position>(), instance);
其中 instance 是 position 类型的组件。如果实例不属于该 registry,则返回 null entity。
依赖关系
registry 类旨在在其成员函数之间创建短路。这极大地简化了 依赖关系 (dependency) 的定义。
例如,每当将 my_type 分配给实体时,以下内容会添加(或替换)组件 a_type:
registry.on_construct<my_type>().connect<&entt::registry::emplace_or_replace<a_type>>();
同样,每当将 my_type 分配给实体时,以下代码会从实体中移除 a_type:
registry.on_construct<my_type>().connect<&entt::registry::remove<a_type>>();
依赖关系很容易如下 断开:
registry.on_construct<my_type>().disconnect<&entt::registry::emplace_or_replace<a_type>>();
还有许多其他类型的 依赖关系。通常,大多数接受实体作为其第一个参数的函数都是用于此目的的良好候选者。
Invoke
invoke helper 允许将 signal 传播 到组件的成员函数,而无需 扩展 它:
registry.on_construct<clazz>().connect<entt::invoke<&clazz::func>>();
它所做的只是为接收到的实体挑选 正确 的组件并调用请求的方法,必要时传递参数。
连接辅助工具
连接 signal 很快就会变得繁琐。
此工具旨在通过对调用进行分组来简化该过程:
entt::sigh_helper{registry}
.with<position>()
.on_construct<&a_listener>()
.on_destroy<&another_listener>()
.with<velocity>("other"_hs)
.on_update<yet_another_listener>();
通过在调用 with 时提供标识符,也支持运行时池,如前一个代码段所示。有关运行时池的更多信息,请参阅以下部分。
显然,此 helper 不会让代码消失,但它至少应该减少最复杂情况下的样板代码。
Handle
Handle 是围绕实体和 registry 的轻量级包装器。它通过提供诸如 get 或 emplace 之类的函数来 复制 registry 的 API。区别在于实体被隐式传递给 registry。
它可以默认构造为一个包含 null registry 和 null entity 的无效 handle。当它包含 null registry 时,调用将执行委托给 registry 的函数会导致未定义行为。如果有疑问,建议使用其隐式转换为 bool 来测试有效性。
Handle 也是非拥有的 (non-owning),这意味着它可以自由复制和移动而不影响其实体(事实上,handle 往往是 trivially copyable 的)。其推论是可变性 (mutability) 成为类型的一部分。
有两个别名使用 entt::entity 作为其默认实体:entt::handle 和 entt::const_handle。
用户还可以轻松地为自定义标识符创建自己的别名:
using my_handle = entt::basic_handle<entt::basic_registry<my_identifier>>;
using my_const_handle = entt::basic_handle<const entt::basic_registry<my_identifier>>;
非 const handle 也可以开箱即用地隐式转换为 const handle,反之则不行。
此类旨在简化函数签名。如果函数接受 registry 和实体并在该实体上执行大部分工作,用户可能需要考虑使用 handle,无论是 const 还是非 const。
Organizer
organizer 类模板支持从一组函数及其对资源的需求创建执行图 (execution graph)。
在任何情况下都不会执行生成的任务。这不是此工具的目标。相反,它们以允许安全执行的图的形式返回给用户。
所有函数都按执行顺序添加到 organizer 中:
entt::organizer organizer;
// 将自由函数添加到 organizer
organizer.emplace<&free_function>();
// 将成员函数和要调用它的实例添加到 organizer
clazz instance;
organizer.emplace<&clazz::member_function>(&instance);
// 直接添加 decayed lambda
organizer.emplace(+[](const void *, entt::registry &) { /* ... */ });
这些是自由函数或成员函数可以接受的参数:
- 对 registry 的可能为 const 的引用。
- 具有 storage 类的任何可能组合的
entt::basic_view。 - 对任何类型
T的可能为 const 的引用(即 context 变量)。
作为参数传递给 emplace 的自由函数和 decayed lambda 的函数类型则是 void(const void *, entt::registry &)。第一个参数是一个可选指针,指向注册时提供的用户定义数据:
clazz instance;
organizer.emplace(+[](const void *, entt::registry &) { /* ... */ }, &instance);
在所有情况下,还可以在创建任务时将其与名称关联。例如:
organizer.emplace<&free_function>("func");
当向 organizer 注册函数时,它访问的所有内容都被视为 资源(view 被 解包,其类型被视为资源)。类型的 constness 也决定了其访问模式(RO/RW)。反过来,这会影响生成的图,因为它影响并行启动任务的可能性。
至于 registry,如果函数没有显式请求它或需要对其的 const 引用,则视为只读访问。否则,视为读写访问。所有函数都将 registry 作为其资源之一。
在注册函数时,用户还可以要求不在函数本身参数列表中的资源。这些被声明为模板参数:
organizer.emplace<&free_function, position, velocity>("func");
同样,用户可以再次通过模板参数覆盖类型的访问模式:
organizer.emplace<&free_function, const renderable>("func");
在这种情况下,即使 renderable 作为非常量出现在函数的参数中,在生成任务图时它也被视为常量。
为了生成任务图,organizer 提供了 graph 成员函数:
std::vector<entt::organizer::vertex> graph = organizer.graph();
图以邻接表 (adjacency list) 的形式返回。每个顶点提供以下功能:
ro_count和rw_count:以只读或读写模式访问的资源数量。ro_dependency和rw_dependency:与底层函数参数关联的 type info 对象。top_level:如果节点是顶层节点(没有进入边),则为 true,否则为 false。info:与底层函数关联的 type info 对象。name:与给定顶点关联的名称(如果有),否则为空指针。callback:指向要执行的函数的指针,其函数类型为void(const void *, entt::registry &)。data:提供给 callback 的可选数据。children:从给定节点可达的顶点,以邻接表内的索引形式表示。
由于 registry 内池和资源的创建不一定是线程安全的,每个顶点还提供一个 prepare 函数,用于设置 registry 以使用创建的图执行:
auto graph = organizer.graph();
entt::registry registry;
for(auto &&node: graph) {
node.prepare(registry);
}
任务的实际调度由用户负责,用户可以使用首选的工具。
Context 变量
每个 registry 都有一个与之关联的 context,这是一个 any 对象映射 (object map),为了方便起见,可以通过类型和 name 访问。不过,name 并不是真正的名字。事实上,它是一个 id_type 类型的数字 id,用作变量的键。接受任何值,甚至是运行时的值。
context 通过 ctx 函数返回,并提供一组最小的功能,包括以下内容:
// 按类型创建一个新的 context 变量并返回它
registry.ctx().emplace<my_type>(42, 'c');
// 按类型创建一个新的命名 context 变量并返回它
registry.ctx().emplace_as<my_type>("my_variable"_hs, 42, 'c');
// 按(推导的)类型插入或分配一个 context 变量并返回它
registry.ctx().insert_or_assign(my_type{42, 'c'});
// 按(推导的)类型插入或分配一个命名 context 变量并返回它
registry.ctx().insert_or_assign("my_variable"_hs, my_type{42, 'c'});
// 从非 const registry 中按类型获取 context 变量作为非 const 引用
auto &var = registry.ctx().get<my_type>();
// 从 const 或非 const registry 中按名称获取 context 变量作为 const 引用
const auto &cvar = registry.ctx().get<const my_type>("my_variable"_hs);
// 按类型重置 context 变量
registry.ctx().erase<my_type>();
// 重置与给定名称关联的 context 变量
registry.ctx().erase<my_type>("my_variable"_hs);
对 context 变量的类型没有严格要求,例如它必须是默认可构造或可移动的。但是,如果使用 name 时提供的类型与变量的类型不匹配,则操作会失败。
对于所有想使用 context 但不想创建元素的用户,还可以使用 contains 和 find 函数:
const bool contains = registry.ctx().contains<my_type>();
const my_type *value = registry.ctx().find<const my_type>("my_variable"_hs);
同样在这种情况下,这两个函数都支持常量类型并接受要查找的变量的 name,at 也是如此。
别名属性
context 还支持为不直接由 registry 管理的现有变量创建 别名 (aliases)。也接受 const 且因此只读的变量。
为此,构造时使用的类型必须是引用类型,并且必须提供左值 (lvalue) 作为参数:
time clock;
registry.ctx().emplace<time &>(clock);
只读别名属性改用 const 类型创建:
registry.ctx().emplace<const time &>(clock);
请注意,insert_or_assign 不支持别名属性,用户必须为此目的使用 emplace 或 emplace_as。
当使用 insert_or_assign 更新别名属性时,它会将属性本身 转换 为非别名属性。
从用户的角度来看,由 registry 管理的变量和别名属性之间没有区别。但是,只读变量不能作为非 const 引用访问:
// 只读变量仅支持 const 访问
const my_type *ptr = registry.ctx().find<const my_type>();
const my_type &var = registry.ctx().get<const my_type>();
别名属性的擦除与任何其他变量一样。同样,也可以为它们分配 name。
Snapshot:完整与连续
此模块附带对序列化 (serialization) 的最低限度支持。
它不直接将组件转换为字节,因为不需要另一个序列化工具。相反,它接受一个具有合适接口(即 archive)的不透明对象,以序列化其内部数据结构并在以后恢复它们。将类型和实例转换为一堆字节的方式完全由 archive 负责,因此也由最终用户负责。
序列化部分的目标是允许用户对整个 registry 进行 dump,或者进行更窄的 snapshot,即仅选择他们感兴趣的组件。
直观地说,用例是不同的。例如,第一种方法适用于本地保存/恢复功能,而后者适用于创建客户端-服务器应用程序并以某种方式在两端之间传输部分表示。
要对 registry 进行 snapshot,请使用 snapshot 类:
output_archive output;
entt::snapshot{registry}
.get<entt::entity>(output)
.get<a_component>(output)
.get<another_component>(output);
不必每次都调用所有函数。在哪种情况下使用哪些函数主要取决于目标。
当 获取 entity 类型时,snapshot 类会序列化所有实体及其版本。
在所有其他情况下,来自给定 storage 的实体和组件将传递给 archive。也支持命名池:
entt::snapshot{registry}.get<a_component>(output, "other"_hs);
get 成员函数还有另一个版本,接受要序列化的实体范围。它可以用于 过滤 掉由于某些原因不应序列化的实体:
const auto view = registry.view<serialize>();
output_archive output;
entt::snapshot{registry}
.get<a_component>(output, view.begin(), view.end())
.get<another_component>(output, view.begin(), view.end());
创建 snapshot 后,主要有两种 方式 来加载它:整体加载和一种 连续模式。
以下部分将详细描述 loader 和 archive。
Snapshot Loader
Snapshot loader 要求目标 registry 为空。它一次性加载所有数据,同时保持实体最初拥有的标识符完整:
input_archive input;
entt::snapshot_loader{registry}
.get<entt::entity>(input)
.get<a_component>(input)
.get<another_component>(input)
.orphans();
不必每次都调用所有函数。在哪种情况下使用哪些函数主要取决于目标。
出于明显的原因,重要的是数据必须按照它们被序列化的完全相同的顺序恢复。
当 获取 entity 类型时,snapshot loader 会恢复所有实体及其在源端最初拥有的版本。
在所有其他情况下,实体和组件在给定 storage 中恢复。如果 registry 不包含该实体,也会相应地创建它。与 snapshot 类一样,也支持命名池:
entt::snapshot_loader{registry}.get<a_component>(input, "other"_hs);
最后,orphans 成员函数会释放恢复后没有组件的实体(如果有的话)。
Continuous Loader
Continuous loader 旨在将数据从源 registry 加载到(可能)非空的目标 registry。loader 在 registry 中容纳多个 snapshot,以一种 连续加载 的方式逐步更新目标。
实体最初拥有的标识符不会转移到目标。相反,loader 在恢复 snapshot 时将远程标识符映射到本地标识符。包装 archive 是自动更新作为组件一部分的标识符的便捷方法(参见下面的示例)。
与 snapshot loader 的另一个区别是,continuous loader 具有必须随时间持久化的内部状态。因此,没有理由将其生命周期限制为临时对象的生命周期:
entt::continuous_loader loader{registry};
input_archive input;
auto archive = [&loader, &input](auto &value) {
input(value);
if constexpr(std::is_same_v<std::remove_reference_t<decltype(value)>, dirty_component>) {
value.parent = loader.map(value.parent);
value.child = loader.map(value.child);
}
};
loader
.get<entt::entity>(input)
.get<a_component>(input)
.get<another_component>(input)
.get<dirty_component>(input)
.orphans();
不必每次都调用所有函数。在哪种情况下使用哪些函数主要取决于目标。
出于明显的原因,重要的是数据必须按照它们被序列化的完全相同的顺序恢复。
当 获取 entity 类型时,loader 会恢复实体组,并在需要时将每个实体映射到本地对应物。对于 loader 尚未注册的每个远程标识符,都会创建一个本地标识符,以使本地实体与远程实体保持同步。
在所有其他情况下,实体和组件在给定 storage 中恢复。如果 registry 不包含该实体,也会相应地跟踪它。与 snapshot 类一样,也支持命名池:
loader.get<a_component>(input, "other"_hs);
最后,orphans 成员函数会释放恢复后没有组件的实体(如果有的话)。
Archives
Archive 必须公开一组预定义的成员函数。API 非常简单,仅包含由 snapshot 类和 loader 调用的一组函数调用运算符。
特别是:
-
Output archive(创建 snapshot 时使用的 archive)公开一个具有以下签名的函数调用运算符以存储实体:
void operator()(entt::entity);其中
entt::entity是 registry 使用的实体类型。
请注意,snapshot 类的所有成员函数还会进行初始调用,以将要存储的集合的 大小 存储在一旁。在这种情况下,函数调用运算符的预期函数类型为:void operator()(std::underlying_type_t<entt::entity>);此外,archive 接受要序列化的组件类型的 (const) 引用。因此,给定类型
T,archive 提供具有以下签名的函数调用运算符:void operator()(const T &);Output archive 可以自由决定如何序列化数据。Registry 完全不受该决定的影响。
-
Input archive(恢复 snapshot 时使用的 archive)公开一个具有以下签名的函数调用运算符以加载实体:
void operator()(entt::entity &);其中
entt::entity是 registry 使用的实体类型。每次调用该函数时,archive 都会从底层存储中读取下一个元素并将其复制到给定变量中。
loader 类的所有成员函数还会进行初始调用,以读取它们将要加载的集合的 大小。在这种情况下,函数调用运算符的预期函数类型为:void operator()(std::underlying_type_t<entt::entity> &);此外,archive 接受要恢复的组件类型的引用。因此,给定类型
T,archive 包含具有以下签名的函数调用运算符:void operator()(T &);每次调用此运算符时,archive 都会从底层存储中读取下一个元素并将其复制到给定变量中。
一个示例统御全局
EnTT 附带了一些示例(实际上是一些测试),展示了如何将著名的序列化库集成为 archive。它在底层使用了 Cereal C++,主要是因为在编写代码时我想了解它是如何工作的。
代码 并非 生产就绪 (production-ready),它既不是唯一的方法,也(可能)不是最好的方法。但是,请随意自行承担风险使用它。
基本思想是将所有内容存储在内存中的一组队列中,然后使用不同的 loader 将所有内容带回 registry。
Storage
组件池是 sparse set 类的 特化版本。每个池包含单个组件类型的所有实例以及分配给它的所有实体。
稀疏数组 (Sparse arrays) 是 分页的 (paged) 以避免浪费内存。组件的紧凑数组 (packed arrays) 也是分页的,以便在添加时保持指针稳定性。而实体的紧凑数组则不是。
所有池都会重新排列其项目,以保持内部数组紧密打包并最大化性能,除非启用了完全的指针稳定性。
Component Traits
在 EnTT 中,几乎所有东西都是可定制的。池也不例外。
在这种情况下,访问所有组件属性的 标准化 方式是 component_traits 类。
库的各个部分通过此类访问组件属性。只要 component_traits 的特化实现了所有必需的功能,就可以将任何类型用作组件。
此类的非特化版本包含以下成员:
in_place_delete:如果存在Type::in_place_delete,对于不可移动类型为 true,否则为 false。page_size:如果存在Type::page_size,对于非空类型为ENTT_PACKED_PAGE,否则为 0。
其中 Type 是任何类型的组件。通过特化上述类并定义其成员,或仅将感兴趣的成员添加到组件定义中来定制属性:
struct transform {
static constexpr auto in_place_delete = true;
// ... 其他数据成员 ...
};
component_traits 类模板负责从提供的类型中 提取 属性。
此外,它可以特化并使用 concept 进行约束,以按类型或按功能进一步定制它。
空类型优化
空类型 T 是指 std::is_empty_v<T> 返回 true 的类型。它们也是可以进行 空基类优化 (EBO) 的类型。
EnTT 以特殊方式处理这些类型,在性能和内存使用方面进行优化。但是,这也带来了一些值得一提的后果。
当检测到空类型时,默认情况下不会实例化它。因此,仅提供分配给它的实体。没有从 storage 或 registry 获取 空类型的方法。View 和 group 也永远不会返回它们的实例(例如,在调用 each 期间)。
另一方面,迭代更快,因为仅考虑分配给该类型的实体。此外,使用的内存更少,主要是因为无论分配给多少个实体,都不存在该组件的任何实例。
更一般地说,库提供的功能都不受影响,除了那些需要返回实际实例的功能。
通过定义 ENTT_NO_ETO 宏可以禁用此优化。在这种情况下,空类型被视为与其他所有类型一样。通过 component_traits 类模板在组件级别设置 page size 是另一种选择性地而非全局禁用此优化的方法。
Void Storage
Void storage(entt::storage<void> 或 entt::basic_storage<void, Entity>)是一种功能齐全的 storage 类型,用于创建不与特定组件类型关联的池。
从技术角度来看,它在所有方面都类似于启用优化时的空类型的 storage。分页和指针稳定性(因为不需要)都被禁用。
但是,这应该优于使用简单的 sparse set。特别是,void storage 提供通常由其他 storage 类型提供的所有功能。因此,它是一个完全有效的池,可与 view 和 group 或在 registry 内使用。
Entity Storage
这种 storage 的组件类型与实体类型相同,例如 entt::storage<entt::entity> 或 entt::basic_storage<Type, Type>。
对于这种类型的池,EnTT 中有一个特定的特化。事实上,实体受不同于组件的规则约束(尽管如果需要仍可由用户定制)。特别是:
- 实体从未真正被 删除。它们被移出 使用中 的实体列表,并且它们的版本会自动更新。
- 其接口中没有
emplace或insert函数。相反,提供了一系列generate函数用于创建或回收实体。 each函数返回一个可迭代对象,以访问 使用中 的实体,即那些未标记为 准备好重用 的实体。要迭代所有实体,必须改为迭代底层的 sparse set。
这种 storage 设计用于可以使用任何其他 storage 的地方,因此可以与 view、group 等结合使用。
保留标识符
由于 entity storage 负责生成标识符,因此也可以请求保留其中一些标识符并永不返回。
通过这样做,用户可以根据需要自主生成和管理它们。
要设置起始标识符,请按如下方式调用 start_from 函数:
storage.start_from(entt::entity{100});
请注意,版本无关紧要,在所有情况下都会被忽略。标识符始终以默认版本生成。
通过如上所述调用 start_from,前 100 个元素将被丢弃,返回的第一个标识符是实体 100 和版本 0 的那个。
Registry 中的唯一性
在 registry 内,entity storage 在所有方面都被视为与其他任何 storage 一样。
因此,可以向其添加 mixin 以及通过 storage 函数检索它。它也可以用作 view 中的 storage(例如,用于 exclude-only view):
auto view = registry.view<entt::entity>(entt::exclude<my_type>);
然而,它也受到几个例外的约束,部分是出于必要,部分是为了易于使用。
特别是,不可能创建多个这种类型的元素。
这意味着用于检索这种 storage 的 name 将被忽略,registry 将永远只向调用者返回相同的元素。例如:
auto &other = registry.storage<entt::entity>("other"_hs);
在这种情况下,标识符将被原样丢弃。该调用在所有方面都等同于以下内容:
auto &storage = registry.storage<entt::entity>();
因为 entity storage 没有名称,所以它也不能通过不透明的 storage 函数检索。
无论如何尝试都没有意义,因为 registry 的类型以及因此其实体类型都是已知的。
最后,当用户要求 registry 提供一个可迭代对象以访问其中的所有 storage 元素时,如下所示:
for(auto [id, storage]: registry.storage()) {
// ...
}
Entity storage 永远不会被返回。这简化了许多任务(例如复制实体),并且完全符合这种 storage 在 registry 内没有标识符的事实。
指针稳定性
为一个、多个或所有组件实现指针稳定性的能力是 EnTT 及其默认 storage 设计的直接结果。
事实上,尽管它包含通常称为 紧凑数组 (packed array) 的内容,但默认 storage 是分页的,并且在空间不足必须重新分配时不会遭受引用失效 (invalidation of references)。
然而,这不足以确保在删除情况下的指针稳定性。因此,还提供了一种 稳定 的删除方法。这种方法通过在删除时创建 tombstone 而不是试图填补创建的空洞来保留元素的位置。
出于性能原因,EnTT 在所有情况下都倾向于 storage 压缩,尽管通常访问组件主要是随机的,或者用户在用户端以非线性顺序遍历池(如在层级结构的情况下)。
换句话说,指针稳定性不是自动的,而是按需启用的。
就地删除
该库开箱即用地支持就地删除 (in-place deletion),从而提供具有完全稳定指针的 storage。这是通过在需要时特化 component_traits 类或将所需属性添加到组件定义来实现的。
当 view 和 group 检测到具有与默认不同的删除策略的 storage 时,它们会相应地进行调整。特别是:
- Group 与稳定 storage 不兼容,甚至拒绝编译。
- 多类型和 runtime view 对 storage 策略完全透明。
- 稳定 storage 类型的单类型 view 提供与多类型 view 相同的接口。例如,只有
size_hint可用。
换句话说,在稳定 storage 的情况下,即使是单类型 view 也提供更通用版本的 view。
在任何情况下,view 本身都不会返回 tombstone。同样,不存在的组件也不会被返回,否则可能会导致 UB。
层级结构及类似情况
EnTT 绝不试图提供具有隐藏或不明确成本的内置方法来促进层级结构 (hierarchies) 的创建。
针对该问题有多种解决方案,例如使用以下类:
struct relationship {
std::size_t children{};
entt::entity first{entt::null};
entt::entity prev{entt::null};
entt::entity next{entt::null};
entt::entity parent{entt::null};
// ... 其他数据成员 ...
};
然而,应该指出的是,为一个、多个或所有类型拥有稳定指针的可能性在许多情况下从根本上解决了层级结构的问题。
事实上,如果某种类型的组件主要以随机顺序或根据层级关系访问,使用直接指针有许多优势:
struct transform {
static constexpr auto in_place_delete = true;
transform *parent;
// ... 其他数据成员 ...
};
此外,一组元素在时间上接近创建并因此落入相邻位置是非常常见的,因此即使在随机访问时也倾向于局部性 (locality)。鉴于 storage 位置的稳定性,这种局部性不会随着时间的推移而牺牲,具有毋庸置疑的性能优势。
运行时的邂逅
EnTT 利用了语言在编译时提供的优势。然而,这也可能有其缺点(熟悉类型擦除 (type erasure) 技术的人都很清楚)。
为了填补这一空白,该库还提供了一堆工具和特性,对于在运行时处理类型和池非常有价值。
统御全局的基类
Storage 类是完全独立的类型。它们通过 mixin 扩展 以添加更多功能(通用的或特定于类型的)。此外,它们提供了一组基本函数,已经允许用户走得很远。
目标是尽可能限制定制的需求,提供绝大多数情况下通常需要的功能。
当通过其基类使用 storage 时(例如,当其实际类型未知时),始终有可能接收到一个 type_info 对象,用于与实体关联的元素类型(如果有的话):
if(entt::type_id<velocity>() == base.info()) {
// ...
}
此外,所有功能都依赖于内部函数,这些函数将调用转发给 mixin。然后,mixin 可以利用通过 bind 设置的任何信息:
base.bind(registry);
bind 函数通过引用或值接受任何元素并将其转发给派生类。
这就是 registry 将自身 传递 给所有支持 signal 的池的方式,也是为什么 storage 继续发送事件而不需要每次都传递 registry 的原因。
除了这些更具体的东西之外,还有几个旨在解决一些常见需求的函数,例如复制实体。
特别是,storage 背后的基类提供了通过不透明指针 获取 与实体关联的值的可能性:
const void *instance = base.value(entity);
同样,非特化的 push 函数接受一个可选的不透明指针,并根据情况表现不同:
- 当指针为空时,函数尝试默认构造要绑定到实体的对象实例,并在成功时返回 true。
- 当指针不为空时,函数尝试复制构造要绑定到实体的对象实例,并在成功时返回 true。
这意味着,从对基类的引用开始,可以在不知道其实际类型的情况下将组件与实体绑定,甚至可以在需要时通过复制初始化它们:
// 逐个组件地创建实体的副本
for(auto &&curr: registry.storage()) {
if(auto &storage = curr.second; storage.contains(src)) {
storage.push(dst, storage.value(src));
}
}
这对于以不透明的方式克隆实体特别有用。此外,功能的解耦允许根据类型过滤或使用不同的复制策略。
传送我吧,Registry
EnTT 允许用户为类型分配一个 name(或者更确切地说,一个数字标识符),然后创建同一类型的多个池:
using namespace entt::literals;
auto &&storage = registry.storage<velocity>("second pool"_hs);
如果未提供名称,则始终返回与给定类型关联的默认 storage。
由于 storage 也是独立的,registry 不会为它们 复制 自己的 API。然而,使用的可能性仍然没有限制:
auto &&other = registry.storage<velocity>("other"_hs);
registry.emplace<velocity>(entity);
other.push(entity);
可以通过 registry 接口完成的任何事情也可以直接在引用的 storage 上完成。
另一方面,涉及所有 storage 的那些调用保证也能 到达 手动创建的 storage:
// 从两个 storage 中移除实体
registry.destroy(entity);
最后,这种类型的 storage 适用于任何 view(如果需要,它也接受同一类型的多个 storage):
// 直接初始化
entt::basic_view direct{
registry.storage<velocity>(),
registry.storage<velocity>("other"_hs)
};
// 连接
auto join = registry.view<velocity>() | entt::basic_view{registry.storage<velocity>("other"_hs)};
直接使用 storage 的可能性与能够创建和使用多个同类型 storage 的自由相结合,为在 运行时 使用 EnTT 打开了大门,而以前这受到很大限制。
Views 与 Groups
View 是一种非侵入式工具,用于处理实体和组件,而不会影响其他功能或增加内存消耗。
Group 是一种侵入式工具,用于提高关键路径的性能,但也需要为此付出代价。
主要有两种 view:编译时(也称为 view)和运行时(也称为 runtime_view)。
前者需要组件(或 storage)类型的编译时列表,并因此可以进行多种优化。后者在运行时使用数字类型标识符构建,迭代速度稍慢。
在这两种情况下,创建和销毁 view 都非常便宜,因为它们没有任何类型的初始化。
Group 分为三种不同的风格:全拥有 (full-owning) group、部分拥有 (partial-owning) group 和 非拥有 (non-owning) group。它们之间的主要区别在于性能。
Group 可以字面上 拥有 一种或多种组件类型。它们被允许重新排列池以加快迭代速度。粗略地说:group 拥有的组件越多,迭代它们的速度就越快。
Views
单类型 view 和多类型 view 的行为不同,并且 API 也略有不同。
单类型 view 经过专门化,在所有情况下都能提供性能提升。没有什么比单类型 view 更快的了。它们只是遍历元素的紧凑(实际上是分页)数组并直接返回它们。
这种 view 还允许获取它们将要返回的确切元素数量。
有关所有详细信息,请参阅内联文档。
多类型 view 迭代至少具有所有给定组件的实体。在构造期间,它们查看每个池中可用的元素数量,并使用最小的集合以加快迭代速度。
这种 view 只允许获取它们将要返回的估计元素数量。
有关所有详细信息,请参阅内联文档。
不需要将 view 存储在一旁,因为它们的构造极其便宜。事实上,当从 const registry 创建 view 时,甚至不鼓励这样做。由于所有 storage 都是延迟初始化的,因此在创建 view 时它们可能不存在。因此,虽然完全可用,但 view 可能包含永远不会用实际 storage 重新初始化的挂起引用。
View 共享通过 registry 创建的方式:
// 单类型 view
auto single = registry.view<position>();
// 多类型 view
auto multi = registry.view<position, velocity>();
还支持通过组件过滤实体:
auto view = registry.view<position, velocity>(entt::exclude<renderable>);
要迭代 view,可以在 range-for 循环中使用它:
auto view = registry.view<position, velocity, renderable>();
for(auto entity: view) {
// 一次一个组件 ...
auto &position = view.get<position>(entity);
auto &velocity = view.get<velocity>(entity);
// ... 多个组件 ...
auto [pos, vel] = view.get<position, velocity>(entity);
// ... 一次性所有组件
auto [pos, vel, rend] = view.get(entity);
// ...
}
或者依赖 each 成员函数一次性迭代实体和组件:
// 通过 callback
registry.view<position, velocity>().each([](auto entity, auto &pos, auto &vel) {
// ...
});
// 使用输入迭代器
for(auto &&[entity, pos, vel]: registry.view<position, velocity>().each()) {
// ...
}
请注意,当通过 callback 接收实体时,也可以将它们从参数列表中排除,这可以进一步提高迭代期间的性能。
由于它们没有被显式实例化,因此在任何情况下都不会返回空组件。
顺便提一下,在单类型 view 的情况下,get 接受但不严格要求模板参数,因为类型是隐式定义的。但是,当未指定类型时,为了与多类型 view 保持一致,将使用 tuple 返回实例:
auto view = registry.view<const renderable>();
for(auto entity: view) {
auto [renderable] = view.get(entity);
// ...
}
注意:在迭代期间,优先使用 view 的 get 成员函数而不是 registry 的 get 成员函数来获取 view 本身迭代的类型。
一次创建,多次复用
View 支持延迟初始化以及 storage 交换 (storage swapping)。
空的(或部分初始化的)view 在转换为 bool 时返回 false(让用户知道它未完全初始化),但它也像任何其他 view 一样按原样工作。
为了逐段初始化 view,它允许用户在可用时注入 storage 类:
entt::storage_for_t<velocity> storage{};
entt::view<entt::get_t<position, velocity>> view{};
view.storage(storage);
如果有多个相同类型的 storage,可以使用要替换的元素的 index 来消除歧义:
view.storage<1>(storage);
从字面上 替换 view 中的 storage 的能力也为使用不同的实体集重用 view 打开了大门。
例如,要基于具有不同特征的两组实体 过滤 view,无需重新初始化任何内容:
entt::view<entt::get<my_type, void>> view{registry.storage<my_type>()};
entt::storage_for_t<void> the_good{};
entt::storage_for_t<void> the_bad{};
// 根据需要初始化上述集合
view.storage(the_good);
for(auto [entt, elem]: view) {
// 这里是好实体及其组件
}
view.storage(the_bad);
for(auto [entt, elem]: view) {
// 这里是坏实体及其组件
}
最后,应该注意的是,缺少 storage 在所有意图和目的上都被视为 空 元素。
因此,get storage(如 entt::get_t)会自动使 view 为空,而 exclude storage(如 entt::exclude_t)将被忽略,就好像过滤器的该部分不存在一样。
仅排除 (Exclude-only)
在 EnTT 中,Exclude-only view 并不是真正的东西。
然而,通过将正确的 storage 组合到简单的 view 中可以实现相同的结果。
如果探究问题的根源,exclude-only view 的目的是返回不满足某些要求的实体。
由于 entity storage 与 exclude-only view 不同,在 EnTT 中 确实 存在,用户可以利用它进行此类查询。它还保证在 registry 中是唯一的,并且在创建 view 时始终可访问:
auto view = registry.view<entt::entity>(entt::exclude<my_type>);
返回的 view 将仅返回没有 my_type 组件的实体,而不管它们具有什么其他组件。
View Pack
View 与 storage 对象以及彼此组合以创建新的、更具体的 查询。
将多个元素组合在一起时返回的类型本身就是一个 view,更一般地说是多组件 view。
组合不同元素试图模仿 ranges:
auto view = registry.view<position>();
auto other = registry.view<velocity>();
const auto &storage = registry.storage<renderable>();
auto pack = view | other | renderable;
类型的 constness 会被保留,它们的顺序取决于 view 组合的顺序。例如,上述 pack 首先返回 position 的实例,然后是 velocity,最后是 renderable。
由于组合元素会生成 view,链可以是任意长度,并且上述类型顺序规则按顺序应用。
迭代顺序
默认情况下,view 沿着包含最少元素数量的池进行迭代。
例如,如果 registry 包含的 velocity 少于 position,则以下 view 返回的元素的顺序取决于 velocity 组件在其池中的排列方式:
for(auto entity: registry.view<position, velocity>()) {
// ...
}
此外,构造 view 时类型的顺序无关紧要。view pack 中 view 的顺序也无关紧要。
然而,可以通过 use 函数 强制 按给定的组件顺序迭代 view:
auto view = registry.view<position, velocity>();
view.use<position>();
for(auto entity: view) {
// ...
}
另一方面,如果用户只想以相反的顺序迭代元素,这对于单类型 view 使用其反向迭代器 (reverse iterators) 是可能的:
auto view = registry.view<position>();
for(auto it = view.rbegin(), last = view.rend(); it != last; ++iter) {
// ...
}
不幸的是,多类型 view 不提供反向迭代器。因此,在这种情况下,必须手动实现此功能或使用单类型 view 来引导迭代。
Runtime Views
多类型 view 迭代至少具有所有给定组件的实体。在构造期间,它们查看每个池中可用的元素数量,并使用最小的集合以加快迭代速度。
它们提供与多类型 view 或多或少相同的功能。然而,它们不公开 get 成员函数,用户应参考生成该 view 的 registry 来访问组件。
有关所有详细信息,请参阅内联文档。
Runtime view 的构造非常便宜,在任何情况下都不应存储在一旁。它们应在创建后立即使用,然后应被丢弃。
要迭代 runtime view,可以在 range-for 循环中使用它:
entt::runtime_view view{};
view.iterate(registry.storage<position>()).iterate(registry.storage<velocity>());
for(auto entity: view) {
// ...
}
或者依赖 each 成员函数迭代实体:
entt::runtime_view{}
.iterate(registry.storage<position>())
.iterate(registry.storage<velocity>())
.each([](auto entity) {
// ...
});
在这两种情况下,性能完全相同。
对于这种 view,也支持通过组件过滤实体:
entt::runtime_view view{};
view.iterate(registry.storage<position>()).exclude(registry.storage<velocity>());
Runtime view 适用于用户在编译时不知道要 使用 哪些类型来迭代实体的情况。registry 的 storage 成员函数在这方面可能很有用。
Groups
Group 旨在一次性迭代多个组件,并提供比多类型 view 更快的替代方案。
Group 克服了其他可用工具的性能,但需要获得组件的所有权 (ownership)。这对其池设置了一些约束。另一方面,group 不是一种增加内存消耗、影响功能并试图为所有可能的组件组合优化迭代的自动化机制。用户可以决定何时为 group 付费以及付费的程度。
Group 最有趣的方面是它们适应 使用模式 (usage patterns)。周围的其他解决方案通常试图优化一切,因为已知在 一切 之中的某处也有我们的使用模式。然而,这在性能和内存使用方面都有不可忽视的成本。具有讽刺意味的是,用户也为他们不想要的东西付出了代价,这不是我喜欢的。更糟糕的是,人们不能轻易禁用这种行为。Group 的工作方式不同,旨在仅在用户发现需要时优化真正的用例。
Group 的另一个很好的特性是它们对内存消耗没有影响,除了非常罕见且应尽可能避免的全非拥有 (full non-owning) group。
所有 group 都在一定程度上影响其组件的创建和销毁。这是因为它们必须 观察 感兴趣的池中的变化,并在需要时为它们拥有的类型 正确 排列数据。
在所有情况下,group 都允许获取它将要返回的确切元素数量。
有关所有详细信息,请参阅内联文档。
不需要将 group 存储在一旁,因为它们的创建极其便宜,尽管有效的 group 可以毫无问题地复制并自由重用。
Group 在第一次被请求时执行初始化步骤,这可能非常昂贵。为了避免这种情况,请考虑在尚未分配任何组件时创建 group。如果 registry 为空,准备 (preparation) 速度极快。
要迭代 group,可以在 range-for 循环中使用它:
auto group = registry.group<position>(entt::get<velocity, renderable>);
for(auto entity: group) {
// 一次一个组件 ...
auto &position = group.get<position>(entity);
auto &velocity = group.get<velocity>(entity);
// ... 多个组件 ...
auto [pos, vel] = group.get<position, velocity>(entity);
// ... 一次性所有组件
auto [pos, vel, rend] = group.get(entity);
// ...
}
或者依赖 each 成员函数一次性迭代实体和组件:
// 通过 callback
registry.group<position>(entt::get<velocity>).each([](auto entity, auto &pos, auto &vel) {
// ...
});
// 使用输入迭代器
for(auto &&[entity, pos, vel]: registry.group<position>(entt::get<velocity>).each()) {
// ...
}
请注意,当通过 callback 接收实体时,也可以将它们从参数列表中排除,这可以进一步提高迭代期间的性能。
由于它们没有被显式实例化,因此在任何情况下都不会返回空组件。
注意:在迭代期间,优先使用 group 的 get 成员函数而不是 registry 的 get 成员函数来获取 group 本身迭代的类型。
全拥有 Groups
Full-owning group 是用户可以期望用于一次性迭代多个组件的最快工具。它直接迭代所有组件,不需要间接寻址 (indirection)。
这种类型的 group 的表现差不多就像用户按顺序访问一堆完全相同排序的组件紧凑数组,没有跳转或分支。
Full-owning group 的创建方式如下:
auto group = registry.group<position, velocity>();
还支持通过组件过滤实体:
auto group = registry.group<position, velocity>({}, entt::exclude<renderable>);
一旦创建,group 就会获得模板参数列表中指定的所有组件的所有权,并根据需要排列它们的池。
一旦创建了 group,就不再允许对拥有的组件进行排序。然而,full-owning group 使用其 sort 成员函数进行排序。对 full-owning group 进行排序会影响其所有实例。
部分拥有 Groups
Partial-owning group 对于它拥有的组件的工作方式类似于 full-owning group,但依赖于间接寻址来获取其他 group 拥有的组件。
这不如 full-owning group 快,但当只有一两个自由组件需要检索时(可能是最常见的情况),它已经比 view 快得多。在最坏的情况下,它无论如何也不会比 view 慢。
Partial-owning group 的创建方式如下:
auto group = registry.group<position>(entt::get<velocity>);
还支持通过组件过滤实体:
auto group = registry.group<position>(entt::get<velocity>, entt::exclude<renderable>);
一旦创建,group 就会获得模板参数列表中指定的所有组件的所有权,并根据需要排列它们的池。相反,通过 entt::get 提供的类型的所有权不会传递给 group。
一旦创建了 group,就不再允许对拥有的组件进行排序。然而,partial-owning group 使用其 sort 成员函数进行排序。对 partial-owning group 进行排序会影响其所有实例。
非拥有 Groups
Non-owning group 通常足够快,肯定比 view 快,并且非常适合大多数情况。然而,它们需要自定义数据结构才能正常工作,并且会增加内存消耗。
根据经验,如果可能,用户应避免使用 non-owning group。
Non-owning group 的创建方式如下:
auto group = registry.group<>(entt::get<position, velocity>);
还支持通过组件过滤实体:
auto group = registry.group<>(entt::get<position, velocity>, entt::exclude<renderable>);
在这种情况下,group 不会接收任何类型组件的所有权。因此,这种类型的 group 通常是性能最差的,但也是唯一可以在任何情况下使用以稍微提高性能的 group。
Non-owning group 使用其 sort 成员函数进行排序。对 non-owning group 进行排序会影响其所有实例。
类型:const、non-const 及其间的所有情况
在构造 view 和 group 时,registry 类提供两个重载:const 版本和非 const 版本。前者仅接受 const 类型作为模板参数,而后者同时接受 const 和非 const 类型。
这意味着由 const registry 生成的 view 和 group 也会将 constness 传播到涉及的类型。例如:
entt::view<entt::get_t<const position, const velocity>> view = std::as_const(registry).view<const position, const velocity>();
相反,考虑非 const view 的以下定义:
entt::view<entt::get_t<position, const velocity>> view = registry.view<position, const velocity>();
在上面的示例中,view 用于访问只读或可写的 position 组件,而 velocity 组件在所有情况下都是只读的。
同样,这些语句都是有效的:
position &pos = view.get<position>(entity);
const position &cpos = view.get<const position>(entity);
const velocity &cpos = view.get<const velocity>(entity);
std::tuple<position &, const velocity &> tup = view.get<position, const velocity>(entity);
std::tuple<const position &, const velocity &> ctup = view.get<const position, const velocity>(entity);
相反,不可能从同一个 view 获取对 velocity 组件的非 const 引用。因此,这些会导致编译错误:
velocity &cpos = view.get<velocity>(entity);
std::tuple<position &, velocity &> tup = view.get<position, velocity>(entity);
std::tuple<const position &, velocity &> ctup = view.get<const position, velocity>(entity);
each 成员函数也将其 constness 传播到其 返回值:
view.each([](auto entity, position &pos, const velocity &vel) {
// ...
});
调用者仍然可以通过 const 引用引用 position 组件,因为语言的规则幸运的是已经允许这样做。
同样的概念也适用于 group。
给我全部
View 和 group 是整个实体列表的狭窄窗口。它们通过根据实体的组件过滤实体来工作。
在某些情况下,可能需要迭代所有仍在使用中的实体,而不管它们的组件如何。这是通过访问 entity storage 来完成的:
for(auto entity: registry.view<entt::entity>()) {
// ...
}
根据经验,如果目标是迭代具有确定组件集的实体,请考虑使用 view 或 group。这些工具通常比使用一堆自定义测试过滤实体要快得多。
在所有其他情况下,这就是要走的路。例如,可以将此 view 与 orphan 成员函数结合使用,以清理孤儿实体(即仍在使用且没有分配组件的实体):
for(auto entity: registry.view<entt::entity>()) {
if(registry.orphan(entity)) {
registry.release(entity);
}
}
通常,迭代所有实体可能会导致性能不佳。不应频繁执行以避免性能下降的风险。
然而,在初始化编辑器或回收挂起的标识符时,这很方便。
允许与不允许的操作
大多数可用的 ECS 不允许在迭代期间创建和销毁实体和组件,也不允许具有指针稳定性。
EnTT 通过一些限制部分解决了这个问题:
- 在大多数情况下,允许在迭代期间创建实体和组件,并且它永远不会使已存在的引用失效。
- 允许在迭代期间删除当前实体或移除其组件,但这可能会使引用失效。对于所有其他实体,销毁它们或移除其迭代的组件是不允许的,并且可能导致未定义行为。
- 当为引导迭代的类型启用指针稳定性时,添加相同类型的实例可能会也可能不会导致涉及的实体被返回。相反,始终允许销毁实体和组件,即使当前未迭代,也没有使任何引用失效的风险。
- 在反向迭代的情况下,在任何情况下都不允许添加或移除元素。它可能很快导致未定义行为。
换句话说,迭代器很少失效。此外,当添加新元素时,组件引用不会失效,而由于 swap-and-pop 策略,它们在销毁时可能会失效,除非引导迭代的类型进行就地删除。
例如,考虑以下代码段:
registry.view<position>().each([&](const auto entity, auto &pos) {
registry.emplace<position>(registry.create(), 0., 0.);
// 添加新实例后引用保持稳定
pos.x = 0.;
});
each 成员函数不会中断(因为迭代器保持有效),任何引用也不会失效。相反,应该更加注意实体的销毁或组件的移除。
使用普通的 range-for 循环并直接从 view 获取组件,或者将实体和组件的删除移到函数末尾以避免悬空指针 (dangling pointers)。
对于所有不提供稳定指针的类型,迭代器也会失效,如果修改或销毁的实体不是迭代器当前返回的实体,也不是新创建的实体,则行为是未定义的。
为了解决这个问题,可能的方法是:
- 将要移除的实体和组件存储在一旁,并在迭代结束时执行操作。
- 使用适当的标签组件 (tag component) 标记实体和组件,指示它们必须被清除,然后执行第二次迭代以逐一清理它们。
此功能的一个显著副作用是,在大多数情况下,所需的分配数量进一步减少。
更高性能,更多约束
Group 是 view 的更快替代方案。然而,性能越高,对允许和不允许的操作的约束就越大。
特别是,group 在极少数情况下增加了对迭代期间创建组件的限制。这发生在非常特殊的情况下。鉴于 group 的性质和范围,这可能不是经常会遇到的事情,但无论如何了解一下是件好事。
首先,必须说明的是,在迭代 group 时创建组件完全不是问题,并且可以像 view 一样自由完成。这同样适用于组件和实体的销毁,适用上述提到的规则。
额外的限制反而出现在迭代 group 拥有的给定组件之外时。在这种情况下,添加属于 group 本身的组件可能会使迭代器失效。对组件和实体的销毁没有进一步的限制。
幸运的是,这并不总是正确的。事实上,它几乎从不正确,并且仅在某些条件下发生。特别是:
- 使用单类型 view 迭代属于 group 的组件类型,并向实体添加将其加入 group 所需的所有组件,可能会使迭代器失效。
- 使用多类型 view 迭代属于 group 的组件类型,并向实体添加将其加入 group 所需的所有组件,可能会使迭代器失效,除非用户指定另一种组件类型用于诱导 view 的迭代顺序(在这种情况下,前者被视为自由类型,不受该限制的影响)。
换句话说,只要类型被视为自由类型(例如,使用多类型 view 以及 partial- 或 non-owning group)或使用其自己的 group 进行迭代,该限制就不存在,但如果该类型用作主导迭代的主要类型,则可能发生。
这是因为 group 拥有其组件的池并在内部组织数据以最大化性能。因此,只有在作为其 group 的一部分或使用多类型 view 和 group 作为自由类型进行迭代时,才能保证拥有组件的完全一致性。
多线程
通常,整个 registry 本身不是线程安全的。由于几个原因,线程安全不是用户应该开箱即用地想要的东西。仅举其中之一:性能。
View、group 以及因此 EnTT 采用的方法是该规则的伟大例外。确实,view、group 和一般的迭代器本身不是线程安全的。因此,用户不应尝试迭代一组组件并同时修改同一组。然而:
- 只要一个线程迭代具有组件
X的实体或从一组实体中分配和移除该组件,另一个线程就可以安全地对组件Y和Z执行相同的操作,并且一切正常。作为一个简单的例子,用户可以自由执行渲染系统并迭代可渲染实体,同时在单独的线程上并发更新物理组件。 - 同样,只要在迭代期间既不分配也不移除组件,单个组件集就可以被多个线程迭代。换句话说,一个假设的移动系统可以启动多个线程,每个线程都将访问携带有关其实体的速度和位置信息的组件。
这种 entity-component systems 可用于单线程应用程序以及异步事务或多线程。此外,典型的基于线程的 ECS 模型不需要完全线程安全的 registry 即可工作。实际上,用户可以使用现有的 registry 实现目标,同时处理大多数常见模型。
由于上述几个原因以及许多未提及的原因,用户完全负责同步(如果需要)。另一方面,他们可以不用诉诸特定的权宜之计。
最后,EnTT 通过一些编译时定义进行配置,以使其某些部分隐式线程安全,粗略地说,只有那些真正有意义且无法扭转的部分。
当将多个线程与 EnTT 一起使用时,除非您确切知道自己在做什么,否则应定义 ENTT_USE_ATOMIC。即使每个线程仅使用线程本地数据也是如此。有关更多信息,请参阅 此部分。
Iterators
对于 view 和 group 返回的迭代器需要特别说明。大多数时候它们满足随机访问迭代器 (random access iterators) 的要求,在所有情况下它们至少满足前向迭代器 (forward iterators) 的要求。
换句话说,它们适合与标准库的并行算法 (parallel algorithms) 一起使用。如果不清楚,这是一件很棒的事情。
例如,这种迭代器与 std::for_each 和 std::execution::par 结合使用,以并行化访问并因此更新由 view 或 group 返回的组件,只要遵守前面讨论的约束:
auto view = registry.view<position, const velocity>();
std::for_each(std::execution::par_unseq, view.begin(), view.end(), [&view](auto entity) {
// ...
});
这可以显著增加吞吐量,甚至无需诉诸随着时间推移难以维护的复杂技巧。
不幸的是,由于标准当前修订版的限制,并行的 std::for_each 仅接受前向迭代器。这意味着库提供的默认迭代器不能返回代理对象 (proxy objects) 作为引用,而 必须 返回实际的引用类型。
这在未来可能会改变,迭代器几乎肯定迟早会默认返回实体及其组件的引用列表。多遍保证 (Multi-pass guarantee) 在任何情况下都不会中断,性能甚至应该从中进一步受益。
Const Registry
Const registry 也是完全线程安全的。这意味着当生成 view 时,它无法延迟初始化缺失的 storage。
原因很容易解释。为了避免要求提前 声明 类型,registry 会延迟为不同的组件创建 storage 对象。然而,这对于线程安全的 const registry 是不可能的。
返回的 view 始终有效,并在调用者的上下文中按预期运行。然而,当从 const registry 创建时,它们可能包含对不存在的 storage 的悬空引用。
因此,如果将这种 view 放在一旁以备第二次使用,它可能会随着时间的推移表现不佳。
因此,如果一般建议是在必要时创建 view 并立即丢弃它们,那么当涉及到从 const registry 生成的 view 时,这几乎成为了一条规则。
幸运的是,当有疑问或有特殊要求时,也有一种方法可以提前实例化 storage 类。
调用 storage 方法等同于 声明 特定的 storage,从而避免遇到问题。对于那些感兴趣的人,还有其他替代方法,例如用于 registry 预热的单线程 tick,但这些并不总是适用的。
在这种情况下,view 永远不会面临变得 无效 的风险。
文档之外
本文档中未列出许多其他特性和函数。
EnTT,特别是其 ECS 部分,处于持续开发中,有些事情可能会被遗忘,有些事情可能是为了减小此文件的大小而故意省略的。不幸的是,有些部分甚至可能已经过时,仍有待更新。
有关更多信息,建议参考代码本身包含的文档或加入官方渠道提问。
运行时反射系统
目录
简介
反射(或更确切地说,它的缺失)是 C++ 领域的热门话题,在 EnTT 的特定场景中,它是一个能解锁许多有趣功能的工具。我曾寻找满足我需求的第三方库,但总是遇到一些我不喜欢的细节:宏、侵入性、过多的内存分配等等。
最终,我决定为 EnTT 编写一个内置的、非侵入式且无宏的运行时反射系统。也许我做得并不比别人好,也许是的,时间会证明一切,但至少我可以围绕它所属的库来定制这个工具,而不是让库去适应工具。
标识符
在处理标识符时,meta 系统不强制用户依赖库提供的工具。它通过提供一套适用于整数值的 API 来实现,这些整数值可以是通过 hashed string 生成的,也可以不是。
这意味着用户可以为 meta 对象分配任何类型的标识符,只要它们是数值。它们是在运行时、编译时生成的,还是通过自定义函数生成的,都无关紧要。
话虽如此,以下部分的一些示例基于本库提供的 hashed_string 类。因此,在提供整数标识符的地方,很可能会使用如下的用户定义字面量:
entt::meta_factory<my_type>{}.type("reflected_type"_hs);
就其本身而言,这完全等同于:
entt::meta_factory<my_type>{}.type(42u);
显然,人类可读的标识符使用起来更方便,也强烈推荐。
反射简述
反射始终从实际的 C++ 类型开始。用户不能反射 虚构的 类型。
meta_factory 类是一切的起点:
entt::meta_factory<my_type> factory{};
返回的值是一个 factory 对象,用于继续构建 meta 类型。
默认情况下,meta 类型与 EnTT 内置的运行时类型识别系统返回的标识符相关联。
但是,也可以为 meta 类型分配自定义标识符:
entt::meta_factory<my_type>{}.type("reflected_type"_hs);
如果需要,在运行时 检索 meta 类型时使用标识符而不是类型。
然而,用户可能只对向反射类型添加功能感兴趣,以便反射系统可以在底层正确使用它,而不希望使该类型变得 可搜索。在这种情况下,只需不调用 type 即可。
Factory 的所有成员函数都返回 factory 本身。它通常用于创建以下内容:
-
构造函数。通过指定 参数列表 将构造函数分配给反射类型。如果返回类型符合预期,也接受自由函数。从客户端的角度来看,自由函数或实际构造函数之间没有任何区别:
entt::meta_factory<my_type>{}.ctor<int, char>().ctor<&factory>();如果可能,会隐式生成 meta 默认构造函数。
-
数据成员。Meta 数据成员是底层类型的实际数据成员,也可以是任何类型的静态和全局变量或常量。从客户端的角度来看,与反射类型关联的所有变量看起来都像是类型本身的一部分:
entt::meta_factory<my_type>{} .data<&my_type::static_variable>("static"_hs) .data<&my_type::data_member>("member"_hs) .data<&global_variable>("global"_hs);data函数需要用于 meta 数据成员的标识符。然后将其用于运行时访问。
数据成员也可以通过 setter 和 getter 对来定义。这些可以是自由函数、类成员或它们的混合。这种方法对于从非 const 数据成员创建只读属性也很方便:entt::meta_factory<my_type>{}.data<nullptr, &my_type::data_member>("member"_hs); -
成员函数。Meta 成员函数是底层类型的实际成员函数,也可以是普通的自由函数。从客户端的角度来看,与反射类型关联的所有函数看起来都像是类型本身的一部分:
entt::meta_factory<my_type>{} .func<&my_type::static_function>("static"_hs) .func<&my_type::member_function>("member"_hs) .func<&free_function>("free"_hs);func函数需要用于 meta 函数的标识符。然后将其用于运行时访问。
支持 meta 函数重载。反射系统会在运行时根据参数类型解析重载函数。 -
基类。基类是指底层类型实际派生自它的类:
entt::meta_factory<derived_type>{}.base<base_type>();反射系统会跟踪这种关系,并在需要时允许在运行时进行隐式转换。换句话说,在任何需要
base_type的地方,也接受derived_type的实例。 -
转换函数。转换函数允许用户定义反射系统在需要时隐式执行的转换:
entt::meta_factory<double>{}.conv<int>();
这就是用户创建 meta 类型所需的全部内容。有关更多详细信息,请参阅内联文档。
Any 来救场
反射系统提供了一种 entt::any 类的 扩展版本(有关更多详细信息,请参阅 core 模块)。
其目的是在现有功能的基础上增加一些特性,以便将其与 meta 类型系统集成,而无需重复代码。
其 API 与 any 类型非常相似。meta_any 类 包装 了许多推断 meta 节点的功能,然后将部分或全部参数转发到底层存储。
在少数显著差异中,meta_any 增加了对容器和类指针类型 (pointer-like types) 的支持,而 any 则没有。
与 any 类似,此类也用于使用 forward_as_meta 或使用 std::in_place_type<T &> 消歧标签为未托管对象创建 别名,以及通过 as_ref 成员函数从现有对象创建别名。此外,它还可以通过 std::in_place 接管作为参数传递的指针的所有权。
然而,与 any 不同的是,meta_any 对空实例和使用 void 初始化的实例区别对待:
entt::meta_any empty{};
entt::meta_any other{std::in_place_type<void>};
虽然 any 将两者都视为空,但 meta_any 将使用 void 初始化的对象视为 有效 对象。这允许区分失败的函数调用和成功但没有返回值的函数调用。
最后,成员函数 try_cast、cast 和 allow_cast 用于将底层对象转换为给定类型(引用或值类型),或 转换 meta_any 以使转换对结果对象可行。
事实上,meta_any 没有 any_cast 的等效物。
享受运行时
一旦构建了反射类型的网络,剩下的就是在运行时在需要的地方使用它。
有几种选项可以搜索反射类型:
// 直接访问反射类型
auto by_type = entt::resolve<my_type>();
// 通过标识符查找反射类型
auto by_id = entt::resolve("reflected_type"_hs);
// 通过 type info 查找反射类型
auto by_type_id = entt::resolve(entt::type_id<my_type>());
还存在一个 resolve 函数的重载,用于一次性迭代所有反射类型。它返回一个可在 range-for 循环中使用的可迭代对象:
for(auto &&[id, type]: entt::resolve()) {
// ...
}
在所有情况下,返回的值都是 meta_type 的实例(可能带有其 id)。这些对象提供了一套 API,用于了解它们的 运行时标识符、迭代与它们关联的所有 meta 对象,甚至构建底层类型的实例。
Meta 数据成员和函数通过它们的标识符访问:
-
Meta 数据成员:
auto data = entt::resolve<my_type>().data("member"_hs);返回的类型是
meta_data,如果没有与给定标识符关联的 meta 数据对象,则可能无效。
meta 数据对象提供了一套 API,用于查询底层类型(例如,了解它是否是 const 或 static)、获取变量的 meta 类型以及设置或获取包含的值。 -
Meta 函数成员:
auto func = entt::resolve<my_type>().func("member"_hs);返回的类型是
meta_func,如果没有与给定标识符关联的 meta 函数对象,则可能无效。
meta 函数对象提供了一套 API,用于查询底层类型(例如,了解它是否是 const 或 static 函数)、了解参数数量、meta 返回类型和参数的 meta 类型。此外,meta 函数对象用于调用底层函数,然后以meta_any对象的形式获取返回值。
这两个函数都在整个 meta 类型层次结构中搜索元素。但是,它们提供了传递第二个布尔参数的选项,以将搜索限制在顶层 meta 类型。
由此获得的所有 meta 对象以及 meta 类型都显式转换为布尔值以检查有效性:
if(auto func = entt::resolve<my_type>().func("member"_hs); func) {
// ...
}
此外,它们中的所有对象(以及一些其他对象,如 meta 基类)都由一堆重载返回,这些重载为调用者提供顶层元素的可迭代范围。例如:
for(auto &&[id, type]: entt::resolve<my_type>().base()) {
// ...
}
Meta 类型也用于 construct 底层类型的实际实例。
特别是,construct 成员函数接受可变数量的参数并搜索匹配项。然后它返回一个 meta_any 对象,该对象可能已初始化也可能未初始化,具体取决于是否找到了合适的构造函数。
转换函数则不可访问。它们在需要时由 meta_any 和 meta 对象在内部使用。
Meta 类型和一般的 meta 对象包含的内容远比上述提到的多。有关更多详细信息,请参阅内联文档。
告诉我你的名称
对于 meta 类型、数据和函数,用户还可以提供自定义 名称 (names):
entt::meta_factory<my_type>{}
.type("type"_hs, "my_type")
.data<&variable>("data"_hs, "variable")
.func<&function>("func"_hs, "function");
提供的 标签 (label) 应该 是一个字符串字面量。库不会进行拷贝。由用户保证名称本身的生命周期。
字符串标识符通过 name 函数从 meta 对象返回:
const char *name = entt::resolve<my_type>().name();
由于大多数情况下不需要将 名称 与与 meta 对象关联的数字标识符区分开来,EnTT 还提供了这些函数的更紧凑版本:
entt::meta_factory<my_type>{}
.type("my_type")
.data<&variable>("variable")
.func<&function>("function");
同样,提供的名称 应该 是一个字符串字面量。然后使用该字符串通过 hashed_string 类生成数字标识符。
尽管支持名称,但没有可用的基于字符串的查找函数。也就是说,类型 (resolve) 以及数据成员 (data) 和函数成员 (func) 只能 通过数字标识符 搜索。
容器支持
运行时反射系统还支持所有类型的容器。
此外,容器 并不一定意味着 C++ 标准库提供的那些容器。事实上,用户定义的数据结构在许多情况下也可以与 meta 系统协同工作。
容器基于一些常见的 traits 自动 检测。
例如,序列容器必须具有返回前向迭代器的 begin/end 对,而关联容器还必须提供 key_type 成员和 find 函数。
如果容器未被识别为容器,仍然可以通过特化模板类 meta_sequence_container_traits 和 meta_associative_container_traits 来提供 适配器 (adapter)。同样,用户可以通过特化正确的 traits 类但不提供任何定义来 抑制 将类型检测为 meta 容器。
标准库容器通常开箱即用地导出为 meta 容器(std::string 除外,它故意不被视为序列容器)。
但是,必须包含头文件 container.hpp,以便在需要时向编译器提供正确的特化。
该文件还包含一些示例,供那些有兴趣使自己的容器对 meta 系统可用的用户参考。
对于 meta 容器,meta_any 类返回正确初始化的代理对象 (proxy objects) 以方便使用。以下是用户如何访问序列容器的代理对象的故意冗长的示例:
std::vector<int> vec{1, 2, 3};
entt::meta_any any = entt::forward_as_meta(vec);
if(any.type().is_sequence_container()) {
if(auto view = any.as_sequence_container(); view) {
// ...
}
}
关联容器的代理对象通过调用 as_associative_container 以相同的方式访问。
实际上不需要执行双重检查。相反,查询 meta 类型或验证代理对象是否有效就足够了。事实上,代理对象可以上下文转换为 bool 以检查有效性。例如,当包装的对象不是容器时,会返回无效的代理对象。
在所有情况下,都不希望用户显式 反射 容器。只需将存在 traits 类特化的容器分配给 meta_any 对象,即可获取其代理对象。
meta_sequence_container 代理对象的接口对于所有类型的序列容器都是相同的,尽管可用功能因情况而异。特别是:
-
value_type成员函数返回元素的 meta 类型。 -
size成员函数以无符号整数值的形式返回容器中的元素数量。 -
resize成员函数允许调整包装容器的大小,并在成功时返回 true。
例如,无法调整固定大小容器的大小。 -
clear成员函数允许清空包装的容器,并在成功时返回 true。
例如,无法清空固定大小的容器。 -
reserve成员函数允许增加包装容器的容量,并在成功时返回 true。
例如,无法增加固定大小容器的容量。 -
begin和end成员函数返回用于直接迭代容器的不透明迭代器:for(entt::meta_any element: view) { // ... }在所有情况下,给定类型为
C的底层容器,返回的元素包含一个类型为C::value_type的对象,因此这取决于实际的容器。
所有 meta 迭代器都是输入迭代器,并且故意不提供间接引用运算符。 -
insert成员函数用于向容器添加元素。它接受一个 meta 迭代器和要插入的元素:auto last = view.end(); // 向容器追加一个整数 view.insert(last, 42);此函数返回一个指向插入元素的 meta 迭代器和一个指示操作是否成功的布尔值。如果是固定大小的容器,或者参数至少不能转换为所需的类型,对
insert的调用可能会静默失败。
由于 meta 迭代器可以上下文转换为 bool,用户可以依赖它们来了解操作是在实际容器上失败还是在上游失败(例如由于参数转换问题)。 -
erase成员函数用于从容器中移除元素。它接受一个指向要移除元素的 meta 迭代器:auto first = view.begin(); // 从容器中移除第一个元素 view.erase(first);此函数返回最后一个被移除元素之后的 meta 迭代器和一个指示操作是否成功的布尔值。如果是固定大小的容器,对
erase的调用可能会静默失败。 -
operator[]用于访问容器元素。它接受单个参数,即要返回的元素的位置:for(std::size_t pos{}, last = view.size(); pos < last; ++pos) { entt::meta_any value = view[pos]; // ... }该函数返回直接引用实际元素的
meta_any实例。直接修改返回的对象会修改容器内的元素。
根据底层的序列容器,此操作可能不那么高效。例如,在std::list的情况下,位置访问会转化为对列表本身的线性遍历(这可能不是用户所期望的)。
同样,meta_associative_container 代理对象的接口对于所有类型的关联容器也是相同的。然而,在仅键 (key-only) 容器的情况下,行为存在一些差异。特别是:
-
key_only成员函数如果包装的容器是仅键容器,则返回 true。 -
key_type成员函数返回键的 meta 类型。 -
mapped_type成员函数对于仅键容器返回无效的 meta 类型,对于所有其他类型的容器返回映射值的 meta 类型。 -
value_type成员函数返回元素的 meta 类型。
例如,对于std::set<int>它返回int的 meta 类型,而对于std::map<int, char>它返回std::pair<const int, char>的 meta 类型。 -
size成员函数以无符号整数值的形式返回容器中的元素数量。 -
clear成员函数允许清空包装的容器,并在成功时返回 true。 -
reserve成员函数允许增加包装容器的容量,并在成功时返回 true。
例如,无法增加标准 map 的容量。 -
begin和end成员函数返回用于直接迭代容器的不透明迭代器:for(std::pair<entt::meta_any, entt::meta_any> element: view) { // ... }在所有情况下,给定类型为
C的底层容器,返回的元素是一个键值对,其中键的类型为C::key_type,值的类型为C::mapped_type。由于仅键容器没有映射类型,它们的 值 只不过是一个无效的meta_any对象。
所有 meta 迭代器都是输入迭代器,并且故意不提供间接引用运算符。虽然访问的键在关联容器中通常是常量,因此按拷贝返回,但值(如果有的话)由直接引用实际元素的
meta_any实例包装。直接修改它会修改容器内的元素。 -
insert成员函数用于向容器添加元素。它获取两个参数,即要插入的键和值:auto last = view.end(); // 向容器追加一个整数 view.insert(last.handle(), 42, 'c');此函数返回一个布尔值,指示操作是否成功。如果参数至少不能转换为所需的类型,对
insert的调用可能会失败。 -
erase成员函数用于从容器中移除元素。它获取单个参数,即要移除的键:view.erase(42);此函数返回一个布尔值,指示操作是否成功。如果参数至少不能转换为所需的类型,对
erase的调用可能会失败。 -
operator[]用于访问容器中的元素。它获取单个参数,即要返回的元素的键:entt::meta_any value = view[42];该函数返回直接引用实际元素的
meta_any实例。直接修改返回的对象会修改容器内的元素。
容器支持是最小化的,但很可能足以满足所有需求。
类指针类型
与容器一样,也可以 告诉 meta 系统哪些类型是 指针。这使得解引用 meta_any 的实例成为可能,从而获得指向对象的轻量级 引用,这些引用也正确地与它们的 meta 类型相关联。
要使 meta 系统将类型识别为 类指针 (pointer-like),用户可以特化 is_meta_pointer_like 类。EnTT 已经导出了一些常见类的特化。特别是:
- 所有类型的原始指针。
std::unique_ptr和std::shared_ptr。- 所有 导出 名为
is_meta_pointer_like的类型成员的类:
实际类型无关紧要,不会以任何方式使用。struct smart_pointer { using is_meta_pointer_like = void; // ... };
必须包含头文件 pointer.hpp,以便在需要时向编译器提供这些特化。
该文件还包含许多示例,供那些有兴趣使自己的类指针类型对 meta 系统可用的用户参考。
当类型被 meta 系统识别为类指针类型时,可以解引用包含这些对象的 meta_any 实例。以下是故意冗长的示例,展示如何使用此功能:
int value = 42;
// 等同于 int * 的 meta 类型
entt::meta_any any{&value};
if(any.type().is_pointer_like()) {
// 等同于 int 的 meta 类型
if(entt::meta_any ref = *any; ref) {
// ...
}
}
不需要执行双重检查。相反,查询 meta 类型或验证返回的对象是否有效就足够了。例如,当包装的对象不是类指针类型时,会返回无效实例。
解引用类指针对象会返回一个 引用 指向对象的 meta_any 实例。修改它意味着直接修改指向的对象(除非返回的元素是 const)。
通常,解引用 类指针类型归结为 *ptr。然而,EnTT 也支持不提供 operator* 的类。特别是:
-
可以通过实现名为
dereference_meta_pointer_like的函数(也可以是模板函数)来利用基于 ADL 查找的解决方案:template<typename Type> Type & dereference_meta_pointer_like(const custom_pointer_type<Type> &ptr) { return ptr.deref(); } -
当无法控制类型的命名空间时,可以将
adl_meta_pointer_like类模板的特化注入到entt命名空间中,以完全绕过 ADL 查找:template<typename Type> struct entt::adl_meta_pointer_like<custom_pointer_type<Type>> { static decltype(auto) dereference(const custom_pointer_type<Type> &ptr) { return ptr.deref(); } };
在所有其他情况下,并且当解引用指针无论指向的类型如何都能按预期工作时,不需要用户干预。
模板信息
如果原始类型是类模板,Meta 类型还提供有关其 性质 的最小信息集。
默认情况下,这开箱即用,不需要用户操作。但是,必须包含头文件 template.hpp,以便在需要时向编译器提供此信息。
Meta 模板信息很容易找到:
// 如果类型被识别为类模板特化,此方法返回 true
if(auto type = entt::resolve<std::shared_ptr<my_type>>(); type.is_template_specialization()) {
// 由 entt::meta_class_template_tag 方便地包装的类模板的 meta 类型
auto class_type = type.template_type();
// 模板参数的数量
std::size_t arity = type.template_arity();
// 第 i 个参数的 meta 类型
auto arg_type = type.template_arg(0u);
}
通常,当需要类型的模板信息时,库提供的信息就足够了。然而,在某些情况下,用户可能需要更多详细信息或不同的信息集。
考虑一个旨在包装函数类型的类模板的情况:
template<typename>
struct function_type;
template<typename Ret, typename... Args>
struct function_type<Ret(Args...)> {};
在这种情况下,与其提供函数类型,不如提供返回类型和解包的参数,就好像它们是原始类模板的不同模板参数一样。
为了实现这一点,用户必须进入库内部,并为类模板 entt::meta_template_traits 提供自己的特化,例如:
template<typename Ret, typename... Args>
struct entt::meta_template_traits<function_type<Ret(Args...)>> {
using class_type = meta_class_template_tag<function_type>;
using args_type = type_list<Ret, Args...>;
};
反射系统不验证信息的准确性,也不推断实际类型和 meta 类型之间的对应关系。
因此,特化按原样使用,其中包含的信息在需要时与适当的类型相关联。
自动转换
在 C++ 中,算术类型之间允许进行许多转换,这使得处理此类数据非常方便。
如果将其转换为向反射系统显式注册,将会导致一长串如下所示的指令:
entt::meta_factory<int>{}
.conv<bool>()
.conv<char>()
// ...
.conv<double>();
对每种有资格进行此类转换的类型重复此操作。这既容易出错又重复。
同样,该语言允许用户将无作用域枚举 (unscoped enums) 静默转换为其底层类型,并提供了对有作用域枚举 (scoped enums) 执行相同操作所需的一切。如果显式完成,将导致以下结果:
entt::meta_factory<my_enum>{}
.conv<std::underlying_type_t<my_enum>>();
幸运的是,所有这些都可以避免。EnTT 为这些类型的转换提供隐式支持:
entt::meta_any any{42};
any.allow_cast<double>();
double value = any.cast<double>();
无需注册,转换会在底层自动进行。涉及 meta 类型的 allow_cast 调用也是如此:
entt::meta_type type = entt::resolve<int>();
entt::meta_any any{my_enum::a_value};
any.allow_cast(type);
int value = any.cast<int>();
这使得处理算术类型以及有作用域或无作用域枚举就像在 C++ 中一样简单。
仍然可以手动设置转换函数,并且这些函数始终优先于自动转换函数。
隐式生成的默认构造函数
通过反射系统创建默认可构造类型的对象,而无需显式注册 meta 类型或其默认构造函数也是可能的。
例如,对于像 int 或 char 这样的原始类型,但不限于它们。
仅对于默认可构造类型,默认构造函数会自动定义并与其 meta 类型关联,无论它们是显式还是隐式生成的。
因此,这就是从其 meta 类型构造整数所需的全部:
entt::resolve<int>().construct();
例如,当 meta 类型是从 meta 容器返回的类型时,这对于在不知道或不必注册实际类型的情况下构建键很有用。
在所有情况下,当用户注册默认构造函数时,它们在搜索期间和调用 construct 成员函数时都是首选。
从 void 到 any
有时用户拥有的只是一个指向已知 meta 类型对象的不透明指针。在这种情况下,能够从中构造一个 meta_any 元素将非常方便。
为此,meta_type 类提供了一个 from_void 成员函数,旨在将不透明指针转换为 meta_any:
entt::meta_any any = entt::resolve(id).from_void(element);
不幸的是,无法对实际类型进行检查。因此,此调用可以被视为带有所有 问题 的 静态转换 (static cast)。
另一方面,从不透明指针构造 meta_any 的能力为一些值得探索的非常有趣的用途打开了大门。
策略:过犹不及
策略 (policies) 是一种编译时指令,可在注册反射信息时使用。
它们的目的是在某些特定情况下要求与默认行为略有不同的行为。例如,在读取给定数据成员时,其值被包装在 meta_any 对象中返回,默认情况下会对其进行拷贝。对于大型对象,或者如果调用者想访问原始实例,这种行为是不可取的。策略就是为了解决这个问题和其他问题而存在的。
目前有几种替代方案可用:
-
as-value 策略,与类型
entt::as_value_t关联。
这是默认策略。通常,不应显式使用它,因为如果未指定其他策略,则会隐式选择它。
在这种情况下,函数的返回值以及作为数据成员公开的属性始终通过专用的包装器按拷贝返回,因此与它们的原始 meta 类型相关联。 -
as-void 策略,与类型
entt::as_void_t关联。
其目的是丢弃 meta 对象的返回值,无论它是什么,从而使其看起来好像其类型是void:entt::meta_factory<my_type>{}.func<&my_type::member_function, entt::as_void_t>("member"_hs);如果在函数中使用很明显,那么在构造函数和数据成员中使用可能就不那么明显了。在第一种情况下,即使仍然调用了构造函数,返回的包装器也始终为空。在第二种情况下,该属性无法被读取。
-
as-ref 和 as-cref 策略,与类型
entt::as_ref_t和entt::as_cref_t关联。
它们允许构建充当未托管对象引用的包装器。访问包含在请求了 引用 的包装器中的对象,可以直接访问用于初始化包装器本身的实例:entt::meta_factory<my_type>{}.data<&my_type::data_member, entt::as_ref_t>("member"_hs);这些策略适用于构造函数(例如,当对象从外部容器获取而不是按需创建时)、数据成员和一般函数。
如果一方面as_cref_t始终强制返回类型为 const,则as_ref_t会 适应 传递对象的 const 属性以及返回类型的 const 属性(如果有)。 -
as-is 策略,与类型
entt::as_is_t关联。
用于将 meta 类型创建代码与调用代码解耦,同时仍保留数据成员和成员函数的定义行为:entt::meta_factory<my_type>{}.func<&my_type::any_member, entt::as_is_t>("member"_hs);对于返回引用类型的数据成员或成员函数,值按具有相同 const 属性的引用返回。在所有其他情况下,值按拷贝返回。
一些用法相当微不足道,但值得注意的是,存在一些不太明显的边缘情况,这些情况反过来可以通过使用策略来解决。
命名常量与枚举
如前所述,data 成员函数用于反射任何类型的常量。
这允许用户为枚举创建 meta 类型,其工作方式与从类构建的任何其他 meta 类型完全相同。同样,在需要时,算术类型会 丰富 具有特殊意义的常量。
由此导出的所有值对用户来说就像是反射类型的常量数据成员。这避免了直接在反射类型的空间中 导出 C++ 中枚举和类之间的区别的需要。
公开常量值或枚举中的元素非常简单:
entt::meta_factory<my_enum>{}
.data<my_enum::a_value>("a_value"_hs)
.data<my_enum::another_value>("another_value"_hs);
entt::meta_factory<int>{}.data<2048>("max_int"_hs);
访问它们也同样简单。只需执行以下操作,就像使用 meta 类型的任何其他数据成员一样:
auto value = entt::resolve<my_enum>().data("a_value"_hs).get({}).cast<my_enum>();
auto max = entt::resolve<int>().data("max_int"_hs).get({}).cast<int>();
所有这一切都在幕后发生,由于 meta_any 类执行的小对象优化 (small object optimization),没有任何内存分配。
用户定义数据
有时(例如,在创建编辑器时),将 traits 或任意 自定义数据 (custom data) 附加到创建的 meta 对象可能很有用。
它们之间的主要区别在于:
- Traits 是简单的用户定义标志,具有更高的访问性能。库为 traits 保留最多 16 位,即 16 个标志用于位掩码,否则为 2^16 个值。
- 自定义数据存储在为用户保留的通用快速访问区域中,库在任何情况下都不会使用该区域。
在所有情况下,此支持目前仅适用于 meta 类型、meta 数据和 meta 函数。
Traits
用户定义的 traits 通过 meta factory 设置:
entt::meta_factory<my_type>{}.traits(my_traits::required | my_traits::hidden);
在上面的示例中,使用了 EnTT 的 bitmask enum 支持,但任何整数值都可以,只要它不超过 16 位。
Traits 可以在不同时间分配。后续对 traits 函数的调用不会重置先前设置的值。但是,用户必须将 factory 重置为感兴趣的 meta 对象:
entt::meta_factory<my_type>{}
.data<&my_type::data_member, entt::as_ref_t>("member"_hs)
.traits(my_traits::internal);
创建后,所有 meta 对象都提供一个名为 traits 的成员函数来获取当前设置的值:
auto value = entt::resolve<my_type>().traits<my_traits>();
请注意,类型在注册时会被擦除,因此在 提取 traits 时必须重复该类型,以便允许库正确 重构 它们。
自定义数据
自定义任意数据通过 meta factory 设置:
entt::meta_factory<my_type>{}.custom<type_data>("name");
执行此操作的方法是将数据类型指定给 custom 函数,并传递必要的参数以正确构造它。
不可能在不同时间分配自定义数据。因此,对 custom 函数的多次调用会覆盖先前的值。但是,可以从 meta 对象读取此值,并使用 factory 更新现有数据,从而根据需要进行有效更新。
同样,如果需要,用户稍后也可以在 meta 对象上设置自定义数据,只要将 factory 重置为感兴趣的 meta 对象即可:
entt::meta_factory<my_type>{}
.func<&my_type::member_function>("member"_hs)
.custom<function_data>("tooltip");
创建后,所有 meta 对象都提供一个名为 custom 的成员函数,以引用或指向元素的指针的形式获取当前设置的值:
const type_data &value = entt::resolve<my_type>().custom();
请注意,返回的对象在转换为请求的类型之前会在 debug 模式下执行额外检查,以避免微妙的 bug。
只有在转换为指针的情况下,此检查才是安全的,并且会返回空指针以通知用户尝试失败。
注销类型
在反射系统中注册的类型也可以被 注销 (unregistered)。这意味着注销其所有数据成员、成员函数、转换函数等。但是,基类不会被注销,因为它们不一定依赖于它。
粗略地说,注销类型意味着断开所有关联的 meta 对象与其的连接,并使其标识符不再可用:
entt::meta_reset<my_type>();
也可以通过其唯一标识符重置类型:
entt::meta_reset("my_type"_hs);
最后,存在一个 meta_reset 函数的非模板重载,它不接受参数并一次性重置所有 meta 类型:
entt::meta_reset();
稍后可以使用完全不同的名称和形式重新注册类型。
Meta context
所有 meta 类型及其部分都在运行时创建并存储在默认 context 中。这是通过 service locator 获取的:
auto &&context = entt::locator<entt::meta_context>::value_or();
就其本身而言,context 是一个不透明的对象,用户能做的不多。但是,用户可以随时用另一个 context 替换现有的 context:
entt::meta_context other{};
auto &&context = entt::locator<entt::meta_context>::value_or();
std::swap(context, other);
这对于测试目的或定义多个具有不同 meta 类型的 context 对象以酌情使用非常有用。
如果 替换 默认 context 还不够,EnTT 还提供将多个外部管理的 context 与运行时反射系统一起使用的能力。
例如,要在默认 context 之外的 context 中创建新的 meta 类型,只需将其作为参数传递给 meta_factory 构造函数:
entt::meta_ctx context{};
entt::meta_factory<my_type>{context}.type("reflected_type"_hs);
通过这样做,新的 meta 类型在默认 context 中不可用,但可以在需要时通过传递新的 context 来使用,例如在创建新的 meta_any 对象时:
entt::meta_any any{context, std::in_place_type<my_type>};
同样,要在默认 context 之外的 context 中搜索 meta 类型,必须将其传递给 resolve 函数:
entt::meta_type type = entt::resolve(context, "reflected_type"_hs)
更一般地说,当使用外部管理的 context 时,始终需要至少在 入口点 向系统提供要使用的 context。
例如,一旦获得了 meta_type 实例,就不再需要四处传递 context,因为 meta 类型会随身携带该信息并最终将其传播到其所有部分。
另一方面,当构造 meta_any 和 meta_handle、创建 factory 或解析 meta 类型时,必须指示库在哪里获取 meta 类型。
配置
目录
简介
随着时间的推移,EnTT 在许多方面已变得几乎完全可定制。这些变量只是定制其工作方式的众多方法之一。
在绝大多数情况下,用户对更改默认参数没有兴趣。对于所有其他情况,可以在下方找到用于在运行时调整库行为的可能配置列表。
定义
所有选项均旨在作为编译器的参数(或编译单元内的用户定义宏,如果首选的话)。
每个参数都可能导致内部库定义。不建议尝试修改这些内部定义,因为与以下选项不同,无法保证它们随时间推移保持稳定。
ENTT_USE_STL
出于测试目的,它强制使用标准库某些部分的内置替代项,否则这些替代项并非总是可用。
EnTT 会自行 检测 这些情况,用户绝不应显式定义此变量。但是,如果需要,仍然可以这样做。
ENTT_NO_EXCEPTION
定义此变量且不为其分配任何值,以关闭 EnTT 中的异常处理。
这大致相当于设置编译器标志 -fno-exceptions,但仅限于此库。
ENTT_USE_ATOMIC
通常,EnTT 不提供支持多线程的原语。许多功能可以在没有任何显式控制的情况下拆分到多个线程,而用户自己知道是否需要同步点。
然而,当从多个线程使用 EnTT 时,即使处理的是本地存储 (local storage),线程之间共享的某些内部静态数据也应该是原子的 (atomic)。定义此宏且不为其分配任何值即可完成此工作。
ENTT_ID_TYPE
entt::id_type 由此定义直接控制,并在库中被广泛使用。
默认情况下,其类型为 std::uint32_t。但是,如果需要,用户可以定义不同的默认类型。
ENTT_SPARSE_PAGE
众所周知,EnTT 的 ECS 模块基于 稀疏集 (sparse sets)。鲜为人知的是,稀疏数组 (sparse arrays) 是分页的 (paged) 以减少内存使用。
页的默认大小(即它们包含的元素数量)为 4096,但如果合适,用户可以对其进行调整。在所有情况下,所选值 必须 是 2 的幂。
ENTT_PACKED_PAGE
与稀疏数组一样,紧凑数组 (packed arrays) 也是分页的。然而,在这种情况下,目的不是减少内存使用,而是在组件创建时保持指针稳定性 (pointer stability)。
页的默认大小(即它们包含的元素数量)为 1024,但如果合适,用户可以对其进行调整。在所有情况下,所选值 必须 是 2 的幂。
ENTT_ASSERT
出于性能原因,EnTT 不使用异常或任何其他控制结构。事实上,它提供的许多功能如果使用不当会导致未定义行为。
为了解决这个问题,库依赖大量 assert 来检测 debug 构建中的错误。默认情况下,它在内部使用 assert。允许用户通过设置此变量来覆盖其行为。
ENTT_ASSERT_CONSTEXPR
通常,constexpr 函数内的 assert 并不是什么大问题。然而,在极端定制的情况下,进行区分可能很有用。
为此,EnTT 引入了一个坦白说命名不佳的变量,以在这方面简化工作。默认情况下,此变量将其参数转发给 ENTT_ASSERT。
ENTT_DISABLE_ASSERT
断言 (assertions) 在启用时反过来可能会在一定程度上影响性能。无论是否重新定义了 ENTT_ASSERT 和 ENTT_ASSERT_CONSTEXPR,都可以通过此定义一次性禁用所有断言。
请注意,ENTT_DISABLE_ASSERT 优先于其他变量的重新定义,因此旨在无论如何都禁用所有检查。
ENTT_NO_ETO
为了减少内存消耗并提高性能,EnTT 的 ECS 模块从不实例化或存储空类型 (empty types)。
使用此变量将这些类型视为与其他所有类型一样,从而为它们创建专用的 storage。
ENTT_NO_MIXIN
EnTT 自动将 mixin 分配给所有 storage 类型,以支持在创建、销毁和修改元素时发出信号 (signaling)。
Mixin 在性能和编译时间方面可能会有(很可能微不足道的)成本。如果不想要,此宏会抑制自动生成。
ENTT_STANDARD_CPP
EnTT 将非标准语言特性与完全兼容的特性混合使用,以提供其某些功能。
此定义阻止库使用非标准技术,即不完全符合标准 C++ 的功能。
虽然在撰写本文时没有已知的可移植性问题,但如果需要,这应该会使库完全可移植。
配置注入
配置变量通过代码提供,或通过专用文件直接从外部注入。
EnTT 在内部使用 __has_include 并查找特定路径,即 <entt/ext/config.h>。这可以由用户通过适当设置 include 路径来提供。
例如,CMake 允许用户使用 target_include_directories 将额外的 include 目录 绑定 到目标。请参阅测试套件,特别是 config_ext 测试以获取实际示例。
容器
目录
简介
标准 C++ 库已经提供了广泛的容器和适配器 (adaptors)。
要做得比它更好非常困难(尽管做得更糟很容易,正如网上许多示例所展示的那样)。
EnTT 绝不试图取代标准库提供的内容。恰恰相反,标准容器的使用已经非常广泛。
然而,该库还试图通过提供一些最初为内部使用而开发的容器和适配器,来填补特性和功能上的空白。
库的这一部分可能会随着时间的推移而不断扩大。然而,目前它还相当小,主要用于满足一些内部需求。
与往常一样,对于提供的所有容器和适配器,均保证了完整的测试覆盖率和长期的稳定性。
容器
Dense map
EnTT 中提供的 dense map 是一种哈希映射 (hash map),旨在返回元素的紧凑数组 (packed array),从而减少迭代期间内存中的跳转次数。
其实现基于 稀疏集 (sparse sets),每个桶 (bucket) 由紧凑数组本身内的隐式列表标识。
其接口与标准库中的对应物(即 std::unordered_map 类)非常接近。
然而,dense map 返回的局部和非局部迭代器都属于输入迭代器 (input iterator) 类别,尽管它们分别建模了 前向迭代器 (forward iterator) 类型和 随机访问迭代器 (random access iterator) 类型的概念。
这是因为它们返回的是一对引用 (pair of references),而不是对 pair 的引用。换句话说,dense map 返回所谓的 代理迭代器 (proxy iterator),其值类型 (value type) 为:
- 对于非 const 迭代器类型:
std::pair<const Key &, Type &>。 - 对于 const 迭代器类型:
std::pair<const Key &, const Type &>。
这与任何标准库 map 返回的内容大相径庭,在寻找无缝替代品 (drop-in replacement) 时应将其考虑在内。
Dense set
EnTT 中提供的 dense set 是一种哈希集合 (hash set),旨在返回元素的紧凑数组,从而减少迭代期间内存中的跳转次数。
其实现基于 稀疏集,每个桶由紧凑数组本身内的隐式列表标识。
其接口在所有方面都与标准库中的对应物(即 std::unordered_set 类)相似。
然而,这种类型的 set 还支持反向迭代 (reverse iteration),因此提供了实现此目的所需的所有函数(例如 rbegin 和 rend)。
适配器
Table
basic_table 类是一个容器适配器 (container adaptor),它同时管理多个顺序容器 (sequential containers),将它们视为同一张表的不同列。
table 别名允许用户仅提供要处理的类型,并使用 std::vector 作为默认的顺序容器。
只提供了一小部分函数,尽管它们与 std::vector 类提供的 API 非常接近。
内部实现有意由容器组成的 tuple 支持,而不是由 tuple 组成的容器。其目的是允许高效地访问单列,而不仅仅是访问表的整个数据集。
当访问一行时,所有数据都以 tuple 的形式返回,其中包含对行本身元素的(可能为 const 的)引用。
同样,当迭代表时,会为每一行返回对表元素引用的 tuple。
图 (graph)
目录
简介
EnTT 并不旨在提供处理图所需的一切。因此,任何在 graph 子模块中寻找这些内容的人都会失望。
但事实恰恰相反。该子模块非常精简,仅包含开发某些工具(如 flow builder)所严格必需的数据结构和算法。
数据结构
正如简介中所预期的,目的不是提供所有可能适合表示和处理图的数据结构。随着时间的推移,可能会添加或完善许多数据结构。然而,我想劝阻任何对此主题抱有紧密排期期望的人。
本节介绍的数据结构主要用于开发和支持同属该子模块的一些工具。
邻接矩阵
邻接矩阵旨在表示有向图或无向图:
entt::adjacency_matrix<entt::directed_tag> adjacency_matrix{};
directed_tag 类型将图 创建 为有向图。还有一个 undirected_tag 对应物将其创建为无向图。
其接口与 C 语言中典型的双重索引略有不同,并提供了一个 C++ 程序员可能更熟悉的 API。因此,元素的访问和修改通过 contains、insert 和 erase 函数进行,而不是对 operator[] 进行双重调用:
if(adjacency_matrix.contains(0u, 1u)) {
adjacency_matrix.erase(0u, 1u);
} else {
adjacency_matrix.insert(0u, 1u);
}
insert 和 erase 都是 幂等 (idempotent) 函数,如果元素已存在或已被删除,则不会产生任何影响。
前者返回一个 std::pair,包含指向该元素的迭代器和一个指示该元素是否为新插入的布尔值。后者返回删除的元素数量(0 或 1)。
邻接矩阵在构造时使用元素(顶点)数量进行初始化,但以后也可以使用 resize 函数调整大小:
entt::adjacency_matrix<entt::directed_tag> adjacency_matrix{3u};
为了访问所有顶点,该类提供了一个名为 vertices 的函数,该函数返回一个适合此目的的可迭代对象:
for(auto &&vertex: adjacency_matrix.vertices()) {
// ...
}
使用以下代码段可获得相同的结果,因为顶点是普通的无符号整数值:
for(auto last = adjacency_matrix.size(), pos = {}; pos < last; ++pos) {
// ...
}
至于访问边,有几个函数可用。
当目的是访问给定邻接矩阵的所有边时,edges 函数返回一个可迭代对象,用于将它们作为顶点对获取:
for(auto [lhs, rhs]: adjacency_matrix.edges()) {
// ...
}
如果目标是访问给定顶点的所有入边 (in-edges) 或出边 (out-edges),则 in_edges 和 out_edges 函数专为此设计:
for(auto [lhs, rhs]: adjacency_matrix.out_edges(3u)) {
// ...
}
这两个函数都期望将要访问(即返回其入边或出边)的顶点作为参数。
最后,邻接矩阵是一个分配器感知 (allocator-aware) 容器,并提供人们期望从此类容器中获得的大部分功能,例如 clear 或 get_allocator 等。
Graphviz dot 语言
作为最流行的格式之一,该库提供了将图转换为 Graphviz dot 代码段的最低限度支持。
最简单的方法是将输出流和图传递给 dot 函数:
std::ostringstream output{};
entt::dot(output, adjacency_matrix);
还可以提供一个回调 (callback),将顶点传递给该回调,并可用于根据需要向输出添加 (dot) 属性:
std::ostringstream output{};
entt::dot(output, adjacency_matrix, [](auto &output, auto vertex) {
out << "label=\"v\"" << vertex << ",shape=\"box\"";
});
当用户想要将外部管理的数据关联到正在转换的图时,第二种模式特别方便。
Flow builder
Flow builder 用于从 tasks 和 resources 创建 execution graphs。
其实现尽可能通用,并且不与库的任何其他部分绑定。
该类被设计为一种 状态机 (state machine),其中附加了特定的 task,并指定了以只读或读写模式访问的 resources。
API 中的大多数函数还返回 flow builder 本身,这符合构建器类的常识 API。
一旦注册了所有 tasks 并将 resources 分配给它们,就会以邻接矩阵的形式向用户返回一个 execution graph。
该图包含以 顶点 (vertices) 形式分配给 flow builder 的所有 tasks。顶点 本身用作索引,以获取注册期间传递的标识符。
Tasks 与 resources
尽管这些术语在文档中被广泛使用,但 flow builder 并没有 tasks 和 resources 的真正概念。
该类主要使用 标识符 (identifiers),即 id_type 类型的值。换句话说,tasks 和 resources 都由整数值标识。
这允许不将类本身与库的其余部分或任何特定的数据结构耦合。另一方面,它要求用户跟踪标识符与操作或实际数据之间的关联。
一旦创建了 flow builder(不需要构造函数参数),首先要做的就是绑定一个 task。这告诉 builder 谁 打算消耗紧随其后指定的 resources:
entt::flow builder{};
builder.bind("task_1"_hs);
该示例使用 EnTT 的 hashed string 为 task 生成标识符。
事实上,使用 id_type 作为标识符类型并非偶然。事实上,它与内部的 hashed string 类非常匹配。此外,如果用户想依赖内部 RTTI 系统,它也是该系统哈希函数返回的相同类型。
然而,作为一个整数值,它让用户在必要时完全自由地依赖自己的工具。
一旦将 task 与 flow builder 关联,它也就相应地分配了只读或读写 resources:
builder
.bind("task_1"_hs)
.ro("resource_1"_hs)
.ro("resource_2"_hs)
.bind("task_2"_hs)
.rw("resource_2"_hs)
如前所述,许多函数返回 builder 本身,因此很容易连接不同的调用。
同样在 resources 的情况下,它们由 id_type 类型的数值标识。如上所述,这种选择并非完全随机。这与库提供的工具非常契合,同时留下了最大的灵活性空间。
最后,ro 和 rw 函数都提供了一个接受迭代器对的重载,以便可以一次性传递一个范围的 resources。
重新绑定 (Rebinding)
flow 类是基于 resource 的,而不是基于 task 的。这意味着图的生成是由 resources 驱动的,而不是由 flow 定义期间 tasks 的 出现 顺序驱动的。
尽管这个概念特别重要,但在绝大多数情况下它几乎无关紧要。然而,当 重新绑定 (rebinding) resources 或 tasks 时,它变得相关。
事实上,没有什么能阻止将元素重新绑定到 flow。
然而,其行为因情况而异,并且有一些值得了解的细微差别。
在不替换 task 的情况下直接重新绑定 resource,会简单地导致该 task 对该 resource 的访问模式被更新:
builder.bind("task"_hs).rw("resource"_hs).ro("resource"_hs)
在这种情况下,resource 以只读模式访问,无论第一次调用 rw 如何。
在幕后,该调用实际上并没有 替换 前一次调用,而是排队在其后,在生成图时覆盖它。因此,大量的 resource 重新绑定甚至可能影响处理时间(很难观察到,但理论上是可能的)。
重新绑定 resources 并将其与 tasks 的更改结合起来,则具有更多的影响。
如前所述,图的生成是从 resources 开始而不是从 tasks 开始的。因此,结果可能不如预期:
builder
.bind("task_1"_hs)
.ro("resource"_hs)
.bind("task_2"_hs)
.ro("resource"_hs)
.bind("task_1"_hs)
.rw("resource"_hs);
这里发生的情况是,resource 首先 看到 来自第一个 task 的只读访问请求,然后是来自第二个 task 的只读请求,最后是来自第一个 task 的读写请求。
尽管这种定义可能会被算作错误,但生成的图可能出乎意料。事实上,它包含一条从第二个 task 发出并指向第一个 task 的单边。
为了直观地理解发生的事情,只需考虑一个 task 永远不会有指向自身的边这一事实。
虽然不明显,但这种方法与其他任何解决方案一样,有其优点和缺点。例如,在基于 resource 的图生成的上下文中,创建循环实际上很简单:
builder
.bind("task_1"_hs)
.rw("resource"_hs)
.bind("task_2"_hs)
.rw("resource"_hs)
.bind("task_1"_hs)
.rw("resource"_hs);
正如预期的那样,这种定义导致创建两条边,从而在两个 tasks 之间定义一个循环。
作为一般规则,强烈建议不要重新绑定 resources 和 tasks,因为如果用户不知道自己在做什么,可能会导致微妙的 bug。
然而,一旦理解了基于 resource 的图生成机制,它就可以为专业用户提供灵活性和一系列原本无法访问的可能性。
Fake resources 与执行顺序
Flow builder 不提供指定一个 task 应该在另一个 task 之前或之后运行的能力。
事实上,resources 上的 注册 顺序也决定了在生成 execution graph 期间处理 tasks 的顺序。
然而,有一种方法可以 强制 两个进程的执行顺序。
简而言之,由于以相反的模式访问 resource 需要顺序调度而不是并行调度,因此可以利用 Fake resources 来主导执行顺序:
builder
.bind("task_1"_hs)
.ro("resource_1"_hs)
.rw("fake"_hs)
.bind("task_2"_hs)
.ro("resource_2"_hs)
.ro("fake"_hs)
.bind("task_3"_hs)
.ro("resource_2"_hs)
.ro("fake"_hs)
此代码段强制 task_1 在 task_2 和 task_3 之前 执行。这是因为前者对另一个 tasks 也想以只读模式访问的 Fake resource 设置了读写要求。
同样,可以强制一个 task 在特定组 之后 运行:
builder
.bind("task_1"_hs)
.ro("resource_1"_hs)
.ro("fake"_hs)
.bind("task_2"_hs)
.ro("resource_1"_hs)
.ro("fake"_hs)
.bind("task_3"_hs)
.ro("resource_2"_hs)
.rw("fake"_hs)
在这种情况下,由于有许多进程想要读取特定的 resource,它们将并行执行,从而强制 task_3 在所有其他 tasks 之后运行。
Sync points
有时,将 sync point(同步点)的角色分配给节点很有用。
无论它是访问新 resources 还是仅仅作为一个分水岭 (watershed),将此角色分配给顶点的过程始终相同。首先将其绑定到 flow builder,然后调用 sync 函数:
builder.bind("sync_point"_hs).sync();
为这种类型的节点分配 标识 (identity) 的选择在于,通常情况下,它们也会对 resources 执行操作。
如果不是这种情况,仍然可以创建分配了空 tasks 的 no-op(无操作)顶点。
Execution graph
一旦正确注册了 resources 及其使用者,此工具的目的就是生成一个 execution graph,该图考虑所有指定的约束,以返回顶点的最佳调度:
entt::adjacency_matrix<entt::directed_tag> graph = builder.graph();
搜索主顶点(即没有入边的顶点)通常是第一步要求:
for(auto &&vertex: graph) {
if(auto in_edges = graph.in_edges(vertex); in_edges.begin() == in_edges.end()) {
// ...
}
}
然后可以通过其他函数(例如 out_edges 以检索给定 task 的子节点,或 edges 以获取标识符)来实例化 execution graph。
service locator
目录
简介
通常,service locator 与它们暴露的 service 紧密绑定。很难定义一个通用的解决方案。
这个小巧的类试图填补这一空白,并免除了为每个应用程序定义不同特定 locator 的负担。
Service locator
service locator 的 API 试图模仿 std::optional,并在其基础上增加了一些额外的功能,例如 allocator 支持。
有几个函数用于设置 service,即 emplace 和 allocate_emplace:
entt::locator<interface>::emplace<service>(argument);
entt::locator<interface>::allocate_emplace<service>(allocator, argument);
区别在于后者期望一个 allocator 作为第一个参数,并使用它来分配 service 本身。
一旦设置了 service,就可以使用 value 函数来检索它:
interface &service = entt::locator<interface>::value();
由于 service 可能未被设置(因此此函数可能导致未定义行为),还提供了 has_value 和 value_or 函数,用于测试 service locator 并在没有 service 时获取 fallback service:
if(entt::locator<interface>::has_value()) {
// ...
}
interface &service = entt::locator<interface>::value_or<fallback_impl>(argument);
所有参数仅在必要时使用,即如果 service 尚不存在,因此构造并返回 fallback service。在所有其他情况下,它们都会被丢弃。
最后,要重置 service,请使用 reset 函数。
Opaque handles
有时,将 service 的副本 转移 (transfer) 到另一个 locator 很有用。例如,在跨 boundaries 工作时,与动态加载的 module 共享 (share) service 是很常见的。
在这种情况下,选择并不多。其中之一是 导出 (export) service 并将其分配给不同 locator 的可能性。
这就是 handle 和 reset 函数的用途。
前者返回一个 opaque object,可用于 导出(或者更确切地说,获取其引用)service。后者还接受一个可选的 handle 参数,然后允许用户通过使用 opaque handle 初始化来重置 service:
auto handle = entt::locator<interface>::handle();
entt::locator<interface>::reset(handle);
值得注意的是,可以获取未初始化 service 的 handle 并将其与其他 locator 一起使用。当然,用户得到的结果只是在其他地方也拥有一个未初始化的 service。
请注意,导出 service 允许用户 共享 当前在 locator 中设置的对象。替换它不会替换该元素,即使某个 service 已使用指向前一个项目的 handle 进行了配置。
换句话说,如果将 audio service 替换为 null object 以使应用程序静音,并且原始 service 是共享的,则此操作不会传播到其他 locator。因此,共享原始 audio service 所有权的 module 仍然能够发出声音。
poly
目录
简介
静态多态 (static polymorphism) 是 C++ 中一个非常强大的工具,尽管有时使用起来较为繁琐。
本模块旨在使其变得简单且易于使用。
该库允许将 concept 定义为接口,由具体类来满足,而无需从公共基类继承。
除其他优点外,这是静态多态的一般优势,也是 poly 类模板提供的通用包装器 (generic wrapper) 的特定优势之一。
其结果是一个可以作为对象本身传递的对象,而不是通过引用或指针传递,这与使用动态多态时的情况不同。
由于 poly 类模板在内部使用 entt::any,它也支持其大部分功能。例如,为现有且未托管的对象创建别名 (aliases) 的可能性。这允许用户在保持对象所有权的同时利用静态多态。
同样,poly 类模板也受益于 entt::any 类提供的小缓冲区优化 (small buffer optimization),因此可以最小化内存分配次数,在可能的情况下完全避免分配。
其他库
有一些关于静态多态的非常有趣的库。
我更喜欢的是:
前者坦白说是一个实验性库,具有许多有趣的想法。我对某些功能在实际项目中的实用性有一些疑问,但也许是我缺乏经验。在我看来,它唯一的缺点是 API,我觉得它比其他解决方案稍微繁琐一些。
后者无疑是本模块的灵感来源。尽管我在最终 API 和某些功能的实现上选择了不同的方案。
无论如何,这些作者都是 C++ 社区的大师,我只能向他们学习。
Concept 与实现
要创建 类型擦除的多态对象包装器(使用 Eric Niebler 引入的术语),首先要做的是定义一个 concept,类型必须遵循该 concept。
为此,该库提供了一个支持推导接口和完全定义接口的单一类。尽管自动推导接口很方便,并允许用户在大多数情况下编写更少的代码,但它有一些局限性。因此,能够通过提供静态虚函数表 (static virtual table) 的自定义定义来绕过推导是很有用的。
一旦定义了接口,就需要一个通用实现来满足该 concept 本身。
同样在这种情况下,该库允许基于类型或类型族 (families of types) 进行定制,以便在必要时能够超越通用情况。
推导接口
这是定义具有推导接口的 concept 的方式:
struct Drawable: entt::type_list<> {
template<typename Base>
struct type: Base {
void draw() { this->template invoke<0>(*this); }
};
// ...
};
它可以通过继承空类型列表 (empty type list) 来识别。
函数也可以是 const、接受任意数量的参数并返回 void 以外的类型:
struct Drawable: entt::type_list<> {
template<typename Base>
struct type: Base {
bool draw(int pt) const { return this->template invoke<0>(*this, pt); }
};
// ...
};
在这种情况下,所有参数都在对 this 的引用之后传递给 invoke,返回值是内部调用返回的任何内容。
至于 invoke,这是一个通过 Base 注入到 concept 中的名称,必须从其继承。由于它也是一个依赖名称 (dependent name),由于语言的规则,不幸的是需要 this-> template 形式。然而,也存在一种通过外部调用的替代方案:
struct Drawable: entt::type_list<> {
template<typename Base>
struct type: Base {
void draw() const { entt::poly_call<0>(*this); }
};
// ...
};
一旦定义了 concept,用户必须提供其通用实现,以告诉系统任何类型如何满足其要求。这是通过 concept 本身内的别名模板完成的。
传递给 invoke 或 poly_call 的模板参数索引引用了此别名的定义方式。
定义接口
完全定义的 concept 与接口被推导的 concept 没有区别,唯一的区别是这次类型列表不为空:
struct Drawable: entt::type_list<void()> {
template<typename Base>
struct type: Base {
void draw() { entt::poly_call<0>(*this); }
};
// ...
};
同样,允许 void 以外的参数和返回值。此外,当要绑定的方法是 const 时,函数类型也必须是 const:
struct Drawable: entt::type_list<bool(int) const> {
template<typename Base>
struct type: Base {
bool draw(int pt) const { return entt::poly_call<0>(*this, pt); }
};
// ...
};
如果函数类型与推导的类型相同,用户为什么要完全定义 concept?
事实上,这是可以通过手动定义静态虚函数表来绕过的限制。
当内容被推导时,存在一个隐式约束。
如果 concept 公开了一个名为 draw、函数类型为 void() 的成员函数,则满足 concept:
- 要么通过公开具有相同名称和相同签名的成员函数的类。
- 要么通过使用接口本身现有成员函数的 lambda。
换句话说,不可能使用不属于接口的函数,即使它们是满足 concept 的类型的一部分。
同样,不可能在静态虚函数表中推导一个函数类型与接口中关联成员函数不同的函数。
显式定义静态虚函数表会抑制推导步骤,并在为 concept 提供实现时允许最大的灵活性。
满足 Concept
concept 的 impl 别名模板用于定义如何满足它:
struct Drawable: entt::type_list<> {
// ...
template<typename Type>
using impl = entt::value_list<&Type::draw>;
};
在这种情况下,声明通用类型的 draw 方法足以满足 Drawable concept 的要求。
支持成员函数和自由函数来满足 concept:
template<typename Type>
void print(Type &self) { self.print(); }
struct Drawable: entt::type_list<void()> {
// ...
template<typename Type>
using impl = entt::value_list<&print<Type>>;
};
同样,只要参数类型和返回类型支持与静态虚函数表中引用的函数类型之间的转换,实际实现在其函数类型上可能有所不同,因为它在内部被擦除。
此外,self 参数不是系统严格要求的,如果不需要,可以为自由函数省略它。
有关更多详细信息,请参阅内联文档。
继承
由于 poly 在 EnTT 中的外观,concept 继承 非常简单。因此,如果需要,构建 concept 层次结构相当容易。
唯一的约束是层次结构中的所有 concept 必须属于同一个 族 (family),即它们必须全部是推导的或全部是定义的。
对于推导的 concept,继承通过几个步骤实现:
struct DrawableAndErasable: entt::type_list<> {
template<typename Base>
struct type: Drawable::type<Base> {
static constexpr auto base = Drawable::impl<Drawable::type<entt::poly_inspector>>::size;
void erase() { entt::poly_call<base + 0>(*this); }
};
template<typename Type>
using impl = entt::value_list_cat_t<
Drawable::impl<Type>,
entt::value_list<&Type::erase>
>;
};
静态虚函数表为空且必须保持为空。
另一方面,type 不再继承自 Base。相反,它将模板参数转发给 基类 公开的类型。在内部,基类静态虚函数表的 大小 用作本地索引的偏移量。
最后,通过 value_list_cat_t 实用工具,实现包括将新函数附加到先前列表。
至于定义的 concept,类型列表以与上述 concept 实现所示类似的方式 扩展。
为此,声明一个允许将 concept 转换为其底层 type_list 对象的函数很有用:
template<typename... Type>
entt::type_list<Type...> as_type_list(const entt::type_list<Type...> &);
定义并非严格要求,因为该函数仅通过 decltype 使用,如下所示:
struct DrawableAndErasable: entt::type_list_cat_t<
decltype(as_type_list(std::declval<Drawable>())),
entt::type_list<void()>> {
// ...
};
与上面类似,type_list_cat_t 用于将底层静态虚函数表与新函数类型连接起来。
其他所有内容则与已展示的内容相同。
实际应用中的静态多态
一旦定义了 concept 和实现,就可以使用 poly 类模板来 包装 满足要求的实例:
using drawable = entt::poly<Drawable>;
struct circle {
void draw() { /* ... */ }
};
struct square {
void draw() { /* ... */ }
};
// ...
drawable instance{circle{}};
instance->draw();
instance = square{};
instance->draw();
此类提供广泛的构造函数,从默认构造函数(返回未初始化的 poly 对象)到拷贝和移动构造函数,以及就地创建对象的能力。
除其他外,还有一个构造函数允许用户将未托管的对象(无论是 const 还是非 const)包装到 poly 实例中:
circle shape;
drawable instance{std::in_place_type<circle &>, shape};
同样,可以从现有对象创建 poly 的非拥有拷贝 (non-owning copies):
drawable other = instance.as_ref();
在这两种情况下,尽管 poly 对象的接口不变,但它不会构造任何元素或负责销毁引用的对象。
还要注意,底层 concept 是通过调用 operator-> 访问的,而不是直接作为 instance.draw() 访问。
这允许用户将包装器的 API 与 concept 的 API 解耦。因此,instance.data() 调用 poly 对象的 data 成员函数,而 instance->data() 直接映射到底层 concept 公开的功能。
存储大小与对齐要求
在底层,poly 类模板使用 entt::any。因此,它可以利用在编译时定义适合小缓冲区优化的存储大小以及对齐要求的可能性:
entt::basic_poly<Drawable, sizeof(double[4]), alignof(double[4])>
默认大小为 sizeof(double[2]),这似乎是太大缓冲区与无法容纳大于整数的缓冲区之间的良好折衷。对齐要求是可选的,默认情况下,对于大小不超过所提供大小的任何对象,采用最严格(最大)的对齐要求。
值得注意的是,提供大小为 0(在所有方面都是可接受的值)将强制系统在所有情况下动态分配包含的对象。
协作式调度器 (cooperative scheduler)
目录
简介
Process 是一种有用的工具,可用于绕过 system 的严格定义,并以不同的方式引入逻辑,通常无需借助其他 component 类型。
EnTT 通过引入几个用于定义和执行协作式 process 的类,为这种范式提供了最小限度的支持。
Process
典型的 task 继承自 process 类模板。派生类还需指定经过时间 (elapsed times) 的预期类型。
Process 应根据需要实现以下成员函数(请注意,除非派生类想要 覆盖 (override) 默认行为,否则并非必须定义这些函数):
-
void update(Delta, void *);每个 tick 调用一次,直到 process 被显式中止 (aborted) 或结束(无论是否有错误)。每个 process 至少应定义它以 正常 工作。
void *参数是指向用户数据(如果有)的不透明指针,在 update 期间直接转发给 process。 -
void succeeded();在成功的情况下调用,紧跟在 update 之后并在同一个 tick 内。
-
void failed();在发生错误的情况下调用,紧跟在 update 之后并在同一个 tick 内。
-
void aborted();仅当 process 被显式中止时调用。不保证它在同一个 tick 内执行。这完全取决于 process 是否被立即中止。
类还可以通过调用 succeed 和 fail,以及 pause 和 unpause process 本身来更改 process 的状态。
所有这些都是公开可用的成员函数,用于轻松管理 process 的生命周期。
出于好奇,这里提供一个最小示例:
struct my_process: entt::process {
using allocator_type = entt::process::allocator_type;
using delta_type = entt::process::delta_type;
my_process(const allocator_type &allocator, delta_type delay)
: entt::process{allocator},
remaining{delay}
{}
void update(delta_type delta, void *) {
remaining -= std::min(remaining, delta);
// ...
if(!remaining) {
succeed();
}
}
private:
delta_type remaining;
};
Continuation
Process 在成功终止后可以跟随其他 process。
这种配对可以在创建时设置,使 process 在概念上彼此独立,同时在运行时将它们组合起来:
my_process process{};
process.then<my_other_process>();
这种方法允许独立开发 process,并将它们组合起来以定义复杂的动作。
例如,延迟操作,其中父 process(如计时器)在时间结束后 调度 (schedule) 子 process(延迟的 task)。
then 函数也接受 lambda,它们在内部与专用的 process 关联:
process.then([](entt::process &proc, std::uint32_t delta, void *data) {
// ...
})
Lambda 函数接受对管理它的 process 的引用(以便能够终止它、暂停它等),加上通常也传递给 update 函数的值。
共享 Process
所有 process 都继承自 std::enable_shared_from_this,以允许与调用者共享。
返回的 smart pointer 是使用与 scheduler 关联的 allocator 创建的,因此也适用于其所有 process。可以通过在 process 本身上调用 get_allocator 来获取这同一个 allocator。
尽可能而言,共享 process 的目的不是为了让调用者管理它。这实际上可能会损害 scheduler 和 process 本身的正常运行。
相反,其目的是允许调用者保存对 process 的有效引用,从而允许他们通过诸如 pause 等调用来干预其生命周期。
Scheduler
协作式 scheduler 运行不同的 process 并帮助管理它们的生命周期。
每个 process 每个 tick 调用一次。如果它终止,则会自动从 scheduler 中移除,并且永远不会再次被调用。否则,它是下一个 tick 再次运行的良好候选者。
Process 也可以有 子节点 (child)。在这种情况下,当父 process 终止时,仅当它成功返回时,才会被其子节点替换。如果发生错误,父 process 及其子节点都会被丢弃。这样,很容易创建一个 process 链 (chain of processes) 来顺序运行。
使用 scheduler 非常简单。要创建它,用户必须仅提供经过时间的类型,完全不需要任何参数:
entt::basic_scheduler<std::uint64_t> scheduler;
否则,对于最常见的情况,也可以使用 scheduler 别名。它使用 std::uint32_t 作为默认类型:
entt::scheduler scheduler{};
该类具有查询其内部数据结构的成员函数,如 empty 或 size,以及一个将其重置为干净状态的 clear 实用工具:
// 检查是否还有正在运行的 process
const auto empty = scheduler.empty();
// 获取仍在运行的 process 数量
entt::scheduler::size_type size = scheduler.size();
// 将 scheduler 重置为其初始状态并丢弃所有 process
scheduler.clear();
要将 process 附加到 scheduler,请使用 process 类型和用于构造它的参数调用 attach 函数:
scheduler.attach<my_process>(_1000u);
Scheduler 还将为其 process 提供其 allocator 作为第一个参数。
对于 lambda 或 functor,所需的签名与 process 的 then 函数中已经看到的签名相同:
scheduler.attach([](entt::process &, std::uint32_t, void *){ /* ... */ });
在这两种情况下,新创建的 process 都通过引用返回,并且其 then 成员函数用于创建顺序运行的 process 链。
作为一个最小使用示例:
// 以 lambda 函数的形式调度一个 task
scheduler.attach([](entt::process &, std::uint32_t, void *) {
// ...
})
// 以另一个 lambda 函数的形式追加一个子节点
.then([](entt::process &, std::uint32_t, void *) {
// ...
})
// 以 process 类的形式追加一个子节点
.then<my_process>(1000u);
要更新 scheduler 并因此更新其所有 process,应使用 update 成员函数:
// 更新所有 process,不提供用户数据
scheduler.update(delta);
// 更新所有 process 并为它们提供自定义数据
scheduler.update(delta, &data);
除了这些函数之外,scheduler 还提供一个 abort 成员函数,用于一次性丢弃所有正在运行的 process:
// 突然中止所有 process ...
scheduler.abort(true);
// ... 或在下一个 tick 优雅地中止
scheduler.abort();
传递给 abort 函数的参数指示是应立即停止执行,还是应在下一个 tick 通知 process。
资源管理
目录
简介
资源管理通常是游戏开发中最关键的部分之一。解决方案通常针对特定应用程序进行调优。存在多种方法,只要它们符合所使用软件的需求,所有这些方法都是完全可行的。
示例包括启动时加载所有内容、按需加载、预取加载等。
EnTT 并不试图为不同情况提供 万能 解决方案。
相反,该库提供了一个最小化的、通用的 resource cache,在许多情况下可能很有用。
Resource、Loader 与 Cache
Resource、loader 和 cache 是为此目的的三个主要参与者。
Resource 是一张图像、一段音频、一段视频或任何其他类型:
struct my_resource { const int value; };
Loader 是一种可调用类型,其目的是加载特定的 resource:
struct my_loader final {
using result_type = std::shared_ptr<my_resource>;
result_type operator()(int value) const {
// ...
return std::make_shared<my_resource>(value);
}
};
其函数调用运算符可以接受任何参数,并应返回声明的 result_type 类型的值(示例中为 std::shared_ptr<my_resource>)。
Loader 还可以重载其函数调用运算符,以便能够根据不同的参数列表构造相同或另一个 resource。
最后,cache 是一个针对特定 resource 和(可选的)loader 定制的类模板特化:
using my_cache = entt::resource_cache<my_resource, my_loader>;
// ...
my_cache cache{};
该类旨在为不同类型的 resource 创建不同的 cache,并以最合适的方式独立管理每一个。
作为一个(非常)简单的示例,音频轨道可以在应用程序的大多数场景中存活,而网格 (meshes) 可能仅与单个场景关联,然后在玩家离开时被丢弃。
Resource Handle
Resource 不会直接返回给调用者。相反,它们被包装在 resource handle 中,即 entt::resource 类模板的实例。
对于已经了解 享元设计模式 (flyweight design pattern) 的人来说,这正是它所实现的。对于其他人来说,现在是复习一些概念的时候了。
本可以使用 shared pointer 作为 resource handle。事实上,默认实现主要映射了其标准对应物的接口,仅在其之上添加了一些内容。
然而,EnTT 中的 handle 被设计为一个独立的类模板。这是由于在标准库中特化类通常是未定义行为,而能够为一个、多个或所有 resource 类型特化 handle 可能随着时间的推移带来帮助。
Loaders
Loader 负责 加载 resource(相当明显)。
默认情况下,它只是一个可调用对象,将其参数转发给 resource 本身。也就是说,一个 直通类型 (passthrough type)。所有工作都交由 resource 本身的构造函数完成。
正如预期的那样,loader 也是完全可定制的。
自定义 loader 是一个至少具有一个函数调用运算符和名为 result_type 的成员类型的类。
Loader 不需要返回 resource handle。只要 return_type 适合构造 handle,那就没问题。
当使用默认 handle 时,它期望一个 resource 类型,该类型可转换为或适合构造 std::shared_ptr<Type>(其中 Type 是实际的 resource 类型)。
换句话说,loader 应返回指向给定 resource 类型的 shared pointer。然而,这不是强制性的。用户可以通过特化 handle 和 loader 轻松绕过此约束。
如果需要,cache 会将其所有参数转发给 loader。这意味着 loader 也可以支持标签分发 (tag dispatching) 以提供不同的加载策略:
struct my_loader {
using result_type = std::shared_ptr<my_resource>;
struct from_disk_tag{};
struct from_network_tag{};
template<typename... Args>
result_type operator()(from_disk_tag, Args&&... args) {
// ...
return std::make_shared<my_resource>(std::forward<Args>(args)...);
}
template<typename... Args>
result_type operator()(from_network_tag, Args&&... args) {
// ...
return std::make_shared<my_resource>(std::forward<Args>(args)...);
}
}
这使得整个加载逻辑相当灵活,并且易于随时间扩展。
Cache 类
Cache 是被要求 连接各个点 的类。
它加载 resource,将它们存储在一旁,并在需要时返回 handle:
entt::resource_cache<my_resource, my_loader> cache{};
在底层,cache 不过是一个映射 (map),其中键值类型为 entt::id_type,而映射值是 loader 返回的任何类型。
因此,它提供了用户期望从 map 获得的大部分功能,例如 empty 或 size 等。同样,它是一个可迭代类型,也支持按 resource id 索引:
for(auto [id, res]: cache) {
// ...
}
if(entt::resource<my_resource> res = cache["resource/id"_hs]; res) {
// ...
}
有关其他函数(如 contains 或 erase)的所有详细信息,请参阅内联文档。
除了此类与 map 共享 的那部分 API 之外,它还在此基础上添加了一些内容,以满足 resource cache 最常见的要求。
特别是,它没有 emplace 成员函数,而是用 load 和 force_load 取而代之(前者仅在 resource 不存在时加载新 resource,而后者在任何情况下都会触发强制加载):
auto ret = cache.load("resource/id"_hs);
// 仅当 resource 之前不存在时为 true
const bool loaded = ret.second;
// 获取返回的迭代器指向的 resource handle
entt::resource<my_resource> res = ret.first->second;
请注意,在上面的示例中,hashed string 是为了方便而使用的。
Resource 标识符不过是整数值。因此,普通数字以及非类 enum 值都被接受。
值得一提的是,cache 的迭代器及其索引运算符返回的是 resource handle,而不是映射类型的实例。
由于 cache 无法控制 loader,并且 resource 也不要求可转换为 bool,因此这些 handle 可能无效。这通常意味着用户逻辑中的错误,但也可能是 预期的 事件。
因此,建议在 debug 中(例如加载时)通过检查验证 handle 的有效性,或在零售版本中使用适当的逻辑。
事件、信号及其中的一切
目录
简介
信号 (signals) 通常是游戏和一般软件架构的核心部分。
它们有助于解耦系统的各个部分,同时允许它们以某种方式相互通信。
所谓的 现代 C++ 提供了一个在这方面可能有用的工具,即 std::function。例如,它可以用于创建 delegates。
然而,无法保证 std::function 不会在底层执行内存分配,这在某些情况下可能会出现问题。此外,它解决了一个问题,但可能无法很好地适应不时出现的其他需求。
如果不需要 std::function 的灵活性和强大功能,或者为其付出的代价太高,EnTT 提供了一整套轻量级类来解决相同及许多其他问题。
Delegate
Delegate 可用作通用调用器,对于自由函数、lambda 以及附带实例的成员函数,均无内存开销。
它不声称是 std::function 的无缝替代品 (drop-in replacement),因此不要期望在任何 std::function 适用的地方都使用它。话虽如此,在许多情况下,它很可能比 std::function 更适合,因此无论如何都期望大量使用它。
其接口非常简单。它提供一个默认构造函数来创建空 delegates:
entt::delegate<int(int)> delegate{};
创建实例所需的是指定 delegate 接受 的函数类型,即它所建模的函数的签名。
然而,尝试通过调用其函数调用运算符来使用空 delegate 会导致未定义行为,或最有可能导致崩溃。
connect 成员函数有几个重载用于初始化 delegate:
int f(int i) { return i; }
struct my_struct {
int f(const int &i) const { return i; }
};
// 将自由函数绑定到 delegate
delegate.connect<&f>();
// 将成员函数绑定到 delegate
my_struct instance;
delegate.connect<&my_struct::f>(instance);
如果需要,delegate 类也接受数据成员。在这种情况下,delegate 的函数类型使得参数列表为空,并且数据成员的值至少可转换为返回类型。
类型等效于 void(T &, args...) 的自由函数也被接受。第一个参数 T & 被视为有效负载 (payload),函数每次被调用时都会接收它。换句话说,这与上述定义完全兼容:
void g(const char &c, int i) { /* ... */ }
const char c = 'c';
delegate.connect<&g>(c);
delegate(42);
函数 g 使用对 c 的引用和 42 调用。然而,delegate 的函数类型仍然是 void(int)。这也是其函数调用运算符的签名。
delegate 类的另一个有趣方面是,它接受参数列表比其函数类型短的函数:
void g() { /* ... */ }
delegate.connect<&g>();
delegate(42);
其中 delegate 的函数类型如上所述为 void(int)。不言而喻,额外的参数在内部会被静默丢弃。这在许多情况下是一个很好的特性,例如当 delegate 类用作信号 - 槽 (signal-slot) 系统的构建块时。
事实上,这种过滤是双向的。该类尝试 首先 传递其前 count 个参数,然后是最后 count 个参数。如果在连接 listener 时有疑问,请注意转换规则!
相反,不支持从 delegate 列表中任意提取参数的函数。其他特性更受青睐,例如支持参数列表兼容但不完全等于 delegate 的函数。
要一次性创建并初始化 delegate,有几个专门的构造函数。由于语言规则,listener 通过 entt::connect_arg 变量模板提供:
entt::delegate<int(int)> func{entt::connect_arg<&f>};
除了 connect 之外,未提供对应的 disconnect。相反,存在一个 reset 成员函数用于清空 delegate。
要判断 delegate 是否为空,可以在任何条件语句中显式使用它:
if(delegate) {
// ...
}
最后,要调用 delegate,应使用函数调用运算符,如上例所示:
auto ret = delegate(42);
在所有情况下,listener 不必严格遵循 delegate 的签名。只要 listener 可以使用给定的参数调用并产生可转换为给定返回类型的结果,一切都能正常工作。
顺便提一下,类的成员函数可能与实例关联,也可能不关联。如果不关联,函数类型的第一个参数必须是成员函数所操作的类的类型,并且在调用 delegate 时显然必须传递该类的实例:
entt::delegate<void(my_struct &, int)> delegate;
delegate.connect<&my_struct::f>();
my_struct instance;
delegate(instance, 42);
在这种情况下,无法 推导 函数类型,因为第一个参数不一定必须是引用(例如,它可以是指针,也可以是 const 引用)。
因此,对于未绑定的成员函数,必须显式声明函数类型。
运行时参数
delegate 类主要设计用于模板参数。然而,由于其设计,它也提供对运行时参数的最小支持。
当这样使用时,某些功能不受支持。特别是:
- 不支持柯里化 (curried) 函数。
- 不支持参数列表与 delegate 不同的函数。
- 返回类型和参数类型 必须 与 delegate 的类型一致,至少可转换 不再足够。
此外,对于给定的函数类型 Ret(Args...),在运行时连接的函数的签名必须为 Ret(const void *, Args...)。
运行时参数既可以传递给 delegate 的构造函数,也可以传递给 connect 成员函数。在这两种情况下都接受一个可选参数。此参数用于在调用时作为 const void * 来回传递任意用户数据。
要 以困难的方式 将函数连接到 delegate:
int func(const void *ptr, int i) { return *static_cast<const int *>(ptr) * i; }
const int value = 42;
// 使用构造函数 ...
entt::delegate delegate{&func, &value};
// ... 或使用 connect 成员函数
delegate.connect(&func, &value);
如果可能,delegate 的类型从函数推导。在这种情况下,由于第一个参数是实现细节,推导出的函数类型是 int(int)。
调用以此方式构建的 delegate 遵循先前解释的相同规则。
Lambda 支持
通常,delegate 类并不在其所有细微差别中完全支持 lambda 函数。原因很简单:delegate 不是 std::function 的无缝替代品。相反,它试图克服后者的问题。
话虽如此,非捕获 (non-capturing) lambda 函数是受支持的,尽管在这种情况下某些功能不可用。
这是支持在运行时连接函数的逻辑结果。因此,lambda 函数遵循相同的规则和限制。
事实上,由于非捕获 lambda 函数会退化为函数指针,它们可以像 普通函数 一样与 delegate 一起使用,并带有可选的有效负载:
my_struct instance;
// 使用构造函数 ...
entt::delegate delegate{+[](const void *ptr, int value) {
return static_cast<const my_struct *>(ptr)->f(value);
}, &instance};
// ... 或使用 connect 成员函数
delegate.connect([](const void *ptr, int value) {
return static_cast<const my_struct *>(ptr)->f(value);
}, &instance);
如上所述,第一个参数 (const void *) 不是 delegate 函数类型的一部分,用于来回分发任意用户数据。换句话说,上述 delegate 的函数类型是 int(int)。
原始访问
虽然不推荐,但 delegate 也允许直接访问存储的可调用函数目标和底层数据(如果有)。
这使得可以绕过 delegate 本身的行为,并在不同实例上强制调用:
my_struct other;
delegate.target(&other, 42);
不言而喻,这种方法 非常 危险,尤其是因为无法知道所包含的函数最初是某个类的成员函数、自由函数还是 lambda。
此功能的另一个可能(且有意义的)用途是通过其描述性 特征 (traits) 来识别特定的 delegate。
Signals
信号处理器 (signal handlers) 使用对类、函数指针和成员指针的引用。Listener 可以是任何类型的对象,用户负责连接和断开它们与 signal 的连接,以避免因不同生命周期而导致的崩溃。另一方面,这种信号处理器的存在不应过多影响性能。
Signals 在内部使用 delegates,因此遵循相同的规则并提供类似的功能。咨询 delegate 类的文档以获取更多信息可能是个好主意。
信号处理器可以作为私有数据成员使用,而无需向类的客户端暴露任何 发布 (publish) 功能。
基本思想是在 signal 本身和 sink 类之间强加清晰的分离,后者是一个用于动态连接和断开 listener 的工具。
信号处理器的 API 很简单。如果在发布内容时向 signal 提供了一个收集器 (collector),则其 listener 返回的所有值都会被字面上 收集 起来供调用者稍后使用。否则,该类就像一个普通的 signal 一样,不时地发出事件。
要创建信号处理器的实例,只需提供它们所引用的函数类型:
entt::sigh<void(int, char)> signal;
Signals 提供所有基本功能,用于了解它们包含多少 listener (size) 或是否至少包含一个 listener (empty),以及用于交换处理器的函数 (swap)。
除此之外,还有成员函数用于通过 sink 以所有形式连接和断开 listener:
void foo(int, char) { /* ... */ }
struct listener {
void bar(const int &, char) { /* ... */ }
};
// ...
entt::sink sink{signal};
listener instance;
sink.connect<&foo>();
sink.connect<&listener::bar>(instance);
// ...
// 断开自由函数
sink.disconnect<&foo>();
// 断开实例的成员函数
sink.disconnect<&listener::bar>(instance);
// 断开实例的所有成员函数(如果有)
sink.disconnect(&instance);
// 一次性丢弃所有 listener
sink.disconnect();
如上所示,listener 不必严格遵循 signal 的签名。只要 listener 可以使用给定的参数调用并产生可转换为给定返回类型的结果,一切都能正常工作。
在所有情况下,connect 成员函数默认返回一个 connection 对象,可用作通过其 release 成员函数断开连接的替代方案。
也可以从 connection 创建 scoped_connection。在这种情况下,一旦对象超出作用域,链接就会自动断开。
一旦附加了 listener(或者即使根本没有 listener),也可以通过 signal 的 publish 成员函数发布事件和一般数据:
signal.publish(42, 'c');
要收集数据,则使用 collect 成员函数:
int f() { return 0; }
int g() { return 1; }
// ...
entt::sigh<int()> signal;
entt::sink sink{signal};
sink.connect<&f>();
sink.connect<&g>();
std::vector<int> vec{};
signal.collect([&vec](int value) { vec.push_back(value); });
assert(vec[0] == 0);
assert(vec[1] == 1);
收集器必须公开一个函数调用运算符,该运算符接受一个参数,其类型是 listener 返回类型可转换的类型。此外,它可以选择返回一个布尔值,true 表示停止收集数据,false 表示继续。这样可以避免在不必要时调用所有 listener。
Functor 也可以代替 lambda 使用。由于收集器在调用 collect 成员函数时被复制,因此在这种情况下应使用 std::ref:
struct my_collector {
std::vector<int> vec{};
bool operator()(int v) {
vec.push_back(v);
return true;
}
};
// ...
my_collector collector;
signal.collect(std::ref(collector));
Event Dispatcher
事件分发器 (event dispatcher) 类允许用户触发即时事件,或稍后一起排队并发布它们:
// 定义通用分发器
entt::dispatcher dispatcher{};
此类延迟实例化其队列。因此,无需提前 声明 事件类型。
Connect、Disconnect、Publish
向分发器注册的 listener 主要有两种类型:自由函数和成员函数。作为模板函数的 lambda 也被接受,并属于第一组。
在所有情况下,listener 接受任何事件类型的 Event & 参数,无论返回值如何。
Listener 通过 connect 直接链接到 sink 对象:
struct an_event { int value; };
struct another_event {};
void on_event(const an_event &event) { /* ... */ }
struct listener {
// 成员函数 listener
void on_event(const another_event &) { /* ... */ }
};
// ...
// 自由函数 listener
dispatcher.sink<an_event>().connect<&on_event>();
listener listener;
// 成员函数 listener
dispatcher.sink<another_event>().connect<&listener::on_event>(listener);
请注意,在事件处理程序内连接 listener 可能会导致未定义行为。
disconnect 成员函数用于一次移除一个 listener 或一次性移除所有 listener:
// 断开自由函数
dispatcher.sink<an_event>().disconnect<&on_event>();
// 断开实例的成员函数
dispatcher.sink<another_event>().disconnect<&listener::on_event>(listener);
// 断开实例的所有成员函数(如果有)
dispatcher.sink<another_event>().disconnect(&listener);
trigger 成员函数用于向迄今为止注册的所有 listener 发送即时事件:
dispatcher.trigger(an_event{42});
dispatcher.trigger(another_event{});
Listener 会立即被调用,执行顺序不保证。此方法可用于推送紧急消息,例如移动应用上的 正在终止 通知。
另一方面,enqueue 成员函数将消息一起排队,并有助于控制它们发送给 listener 的时机:
dispatcher.enqueue<an_event>(42);
dispatcher.enqueue(another_event{});
事件被存储在一旁,直到调用 update 成员函数:
// 一次性发出给定类型的所有事件
dispatcher.update<an_event>();
// 一次性发出迄今为止排队的所有事件
dispatcher.update();
这样,用户可以将分发器嵌入循环中,并字面上每 tick 向系统分发一次事件。
Named Queues
分发器内的所有队列默认与事件类型关联,然后从中检索。
然而,可以创建具有不同 名称 的队列(因此也可以为单个类型创建多个队列)。事实上,几乎所有函数也都接受一个额外的参数。例如:
dispatcher.sink<an_event>("custom"_hs).connect<&listener::receive>(listener);
在这种情况下,术语 名称 被误用,因为这些是 id_type 类型的实际数字标识符。
此规则的一个例外是 enqueue 函数。它没有额外的参数,而是有一个不同的函数:
dispatcher.enqueue_hint<an_event>("custom"_hs, 42);
这主要是由于模板参数推导规则,并且没有真正(优雅)的方法来避免它。
Event Emitter
一个通用的事件发射器 (event emitter),主要考虑用于处理异步内容的情况。
最初设计用于满足 uvw(用现代 C++ 编写的 libuv 包装器)的需求,后来经过调整以包含在本库中。
要创建发射器类型,派生类必须如下继承基类:
struct my_emitter: emitter<my_emitter> {
// ...
}
不同事件的处理程序在运行时动态创建。无需提前指定可接受事件的完整列表。
此外,每当发布事件时,发射器还会将其自身的引用传递给其 listener。
要创建发射器的新实例,不需要任何参数:
my_emitter emitter{};
Listener 是可移动且可调用的对象(自由函数、lambda、functor、std::function 等),其函数类型与以下内容兼容:
void(Type &, my_emitter &)
其中 Type 是它们想要接收的事件类型。
要将 listener 附加到发射器,存在 on 成员函数:
emitter.on<my_event>([](const my_event &event, my_emitter &emitter) {
// ...
});
同样,reset 成员函数用于断开给定类型的 listener,而 clear 用于一次性断开所有 listener:
// 重置 my_event 的 listener
emitter.erase<my_event>();
// 重置所有 listener
emitter.clear()
要将事件发送给在给定类型上注册的 listener,应使用 publish 函数:
struct my_event { int i; };
// ...
emitter.publish(my_event{42});
最后,empty 成员函数测试事件发射器是否至少注册了一个 listener,而 contains 用于检查给定事件类型是否与有效 listener 关联:
if(emitter.contains<my_event>()) {
// ...
}
此类引入了一个基于事件和 listener 的 nice-to-have 模型。
更一般地说,当派生类 包装 异步操作时,它是一个方便的工具,但并不局限于此类用途。
跨越边界使用 EnTT
目录
跨越边界工作
历史上,EnTT 在 Windows 上跨边界使用,以及在 GNU/Linux 上默认可见性 (visibility) 设置为 hidden 时跨边界使用,一直存在一个限制。该限制主要是由于一个用于为不同类型分配唯一的、顺序的标识符的自定义工具引起的。
幸运的是,如今 EnTT 可以顺畅地跨边界工作。
默认顺畅,除非另有证明
EnTT 中的许多类为了其目的广泛使用了类型擦除 (type erasure)。这引发了识别类型已被擦除的对象的需求。
type_hash 类模板是生成标识符并使其可供库的其余部分使用的方式。通常,这个类很少引起关注。唯一的例外是当标识符之间发生冲突时(尽管这绝对不常见),或者当 EnTT 提供的默认解决方案不适合用户的目的时。
专门介绍 type_info 的部分包含了以简洁优雅的方式解决该问题的所有详细信息。请参阅特定文档。
在使用链接库 (linked libraries) 时,编译定义 ENTT_API_EXPORT 和 ENTT_API_IMPORT 用于导入或导出符号,从而使一切都能良好地跨边界工作。
另一方面,当使用不导出任何符号的插件 (plugins) 或共享库 (shared libraries) 时,一切也应该顺畅运行。
对于需要更多详细信息的人,测试套件包含许多涵盖最常见情况的示例(有关所有详细信息,请参阅 lib 目录)。
不言而喻,不可能涵盖 所有 可能的情况。然而,所提供的示例有望作为所有情况的基础。
Meta context
在跨边界使用时,运行时反射系统 (runtime reflection system) 值得特别一提。
由于它已经链接到元素所附加的静态 context,并且不同的 context 彼此不相关,因此必须 共享 (share) 它们以允许跨边界使用 meta types。
幸运的是,共享 context 也非常简单。首先,在主空间 (main space) 中获取本地 context:
auto handle = entt::locator<entt::meta_ctx>::handle();
然后,将其传递给接收空间 (receiving space),接收空间将其设置为默认 context,从而丢弃或搁置本地 context:
entt::locator<entt::meta_ctx>::reset(handle);
从现在起,两个空间都引用同一个 context,并且所有新的 meta types 都附加到它,无论它们在哪里创建。
请注意,替换 (replacing) 主 context 也不会将更改传播到边界之外。换句话说,替换 context 会导致两侧解耦 (decoupling),从而导致内容出现分歧。
内存管理
由于内存管理,还存在另一个可能导致令人头疼的微妙问题。
它可能发生在按需动态创建对象池(例如 components 或 events)的地方。当使用依赖相同动态运行时 (dynamic runtime) 的链接库时,这通常不是问题。然而,在插件 (plugins) 或静态链接运行时 (statically linked runtimes) 的情况下,它可能会发生。
例如,想象在主可执行文件 (main executable) 中创建一个 registry 实例并将其与插件共享。如果后者开始使用前者未知的 component,则在首次使用时会在 registry 内创建一个专用池。
可以猜到,这个池是在与 registry 不同的边界另一侧实例化的。因此,该实例现在正在管理来自不同空间的内存,如果处理不当,这可能很快导致崩溃。
为了克服这种风险,建议使用定义良好的接口,使基本类型 (fundamental types) 穿过边界,适时且适当地隔离 EnTT 类的实例。
请参阅测试套件中的一些示例,阅读在线提供的有关此类问题的文档,或咨询已有此类经验的人以避免出现问题。
常见问题解答
目录
简介
这是一个不断更新的章节,我试图在此处汇总最常被问到的问题的答案。
如果您在这里找不到答案,有两种情况:还没有人问过,或者本章节需要更新。在这两种情况下,您都可以 提交新 issue,或者进入 Gitter 频道 或 Discord 服务器 寻求帮助。
可能已经有人为您准备了答案,随后我们可以将这部分内容整合到文档中。
FAQ
为什么我在 Windows 上的 debug 构建如此缓慢?
EnTT 是一个实验性项目,我也用它来跟进语言和标准库的最新修订版。因此,您正在使用的某些类很可能在底层使用了标准容器。
不幸的是,众所周知,标准容器在 debug 模式下的性能并不好(原因超出了本文档的范畴),而且在 Windows 上似乎更是如此。幸运的是,这也可以在很大程度上得到缓解,在许多情况下都能取得良好的效果。
首先,在 Windows 项目中需要做两件事:
- 禁用
/JMC选项(Just My Code 调试),该选项从 Visual Studio 2017 15.8 版开始提供。 - 将
_ITERATOR_DEBUG_LEVEL宏设置为 0。这将禁用检查迭代器 (checked iterators) 和迭代器调试 (iterator debugging)。
此外,设置 ENTT_DISABLE_ASSERT 变量或重定义 ENTT_ASSERT 宏以禁用 EnTT 内部的 debug 检查:
#define ENTT_ASSERT(...) ((void)0)
引入这些 assert 是为了帮助用户,但它们需要访问底层容器,因此在某些情况下可能会破坏性能。
进行这些更改后,在大多数情况下 debug 性能应会有足够的提升。如果您想要更好的性能,还可以切换到优化级别 O0 或最好是 O1。
如何用 component 表示层级结构?
这是任何人在开始使用 entity-component-system 架构模式时最先提出的问题之一。
解决该问题有几种方法,最佳方法主要取决于面临的实际问题。在所有情况下,如何实现并不严格依赖于所使用的库,但后者肯定允许或不允许使用不同的技术,具体取决于数据的布局方式。
我试图描述一些适合 EnTT 模型的方法。这篇文章是试图 探索 该问题的系列文章的第一篇。未来可能还会有更多文章。
此外,EnTT 还提供了创建稳定 storage 类型的可能性,从而为一个、所有或某些 component 提供指针稳定性 (pointer stability)。在创建层级结构等场景时,这是迄今为止最方便的解决方案。有关更多详细信息,请参阅库的 ECS 部分文档,特别是关于 component_traits 类的内容。
自定义 entity 标识符:赞成还是反对?
至少在两种情况下,自定义 entity 标识符绝对是个好主意:
- 如果
std::uint32_t对您的目的来说不够大,因为这是entt::entity的底层类型。 - 如果您想避免在使用多个 registry 时发生冲突。
标识符可以通过 enum class 和定义了 std::uint32_t 或 std::uint64_t 类型的 entity_type 成员的 class type 来定义。
事实上,这是一个等同于 entt::entity 的定义:
enum class entity: std::uint32_t {};
可定义的标识符数量没有限制。
警告 C4003:min、max 与宏
在 Windows 上,某个头文件定义了两个宏 min 和 max,这可能会导致它们与标准库中的对应物发生冲突,从而在编译期间引发错误。
这是一个相当大的问题。但幸运的是,这不是 EnTT 的问题,并且有一个相当简单的解决方案。
它包含在包含任何其他头文件之前定义 NOMINMAX 宏,以消除多余的定义:
#define NOMINMAX
有关更多详细信息,请参阅 此 issue。
标准库与不可拷贝类型
EnTT 内部使用 trait std::is_copy_constructible_v 来检查 component 是否真正可拷贝。然而,该 trait 并没有真正检查类型是否实际可拷贝。相反,它只检查是否存在合适的拷贝构造函数和拷贝运算符。
由于标准的一些特性,这可能会导致令人惊讶的结果。
例如,std::vector 定义了一个条件启用的拷贝构造函数,具体取决于值类型是否可拷贝。因此,std::is_copy_constructible_v 对以下特化 (specialization) 返回 true:
struct type {
std::vector<std::unique_ptr<action>> vec;
};
然而,在特化时,拷贝构造函数实际上被禁用了。因此,尝试将此类型的实例分配给 entity 可能会触发编译错误。
作为一种解决方法,用户可以显式将该类型标记为不可拷贝 (non-copyable)。这也会抑制移动构造函数和运算符的隐式生成,因此必须相应地将它们默认化 (defaulted):
struct type {
type(const type &) = delete;
type(type &&) = default;
type & operator=(const type &) = delete;
type & operator=(type &&) = default;
std::vector<std::unique_ptr<action>> vec;
};
请注意,因此聚合初始化 (aggregate initialization) 也会被禁用。
幸运的是,这种类型的技巧非常罕见。坏消息是,由于语言的设计,无法在库级别处理它。另一方面,语言本身也提供了一种缓解该问题的方法,使其变得可控。
哪些函数触发哪些 signal
Storage 类提供三个 signal,在特定操作后发出。不过,也许并非所有人都清楚这些操作是什么。
如果不清楚,您可以在下方找到一份用于此目的的 备忘录 (vademecum):
on_created(注:API 实际为on_construct)在 component 首次被添加(既未修改也未替换)到 entity 时调用。on_update在现有 component 被修改或替换时调用。on_destroyed(注:API 实际为on_destroy)在 component 从 entity 中显式或隐式移除时调用。
最具争议的函数包括 emplace_or_replace 和 destroy。然而,遵循上述规则,很容易知道会发生什么。
在第一种情况下,如果 entity 没有该 component,则调用 on_created,否则替换后者并因此触发 on_update。至于第二种情况,component 从其 entity 中移除,因此在回收时被释放。这意味着对于被销毁的 entity 拥有的每个 component,都会触发 on_destroyed。
同一 component 的重复 storage
这种情况很少见,但有时您可能会看到“重影”,尤其是在涉及 storage 时。这可能是由于分配给各种 component 类型的哈希发生冲突(独一无二),或者由于您的编译器存在 bug(显然更常见)。
无论原因如何,EnTT 提供了一个定制点 (customization point),在这种情况下也可作为解决方案:
template<>
struct entt::type_hash<Type> final {
[[nodiscard]] static consteval id_type value() noexcept {
return hashed_string::value("Type");
}
[[nodiscard]] consteval operator id_type() const noexcept {
return value();
}
};
直接特化 type_hash 会绕过 EnTT 提供的默认实现,从而避免任何可能的冲突或编译器 bug。
类似项目
目录
简介
有许多与 EnTT 类似的项目,既有开源的,也有非开源的。
有些甚至借鉴了本库的一些想法,并用不同的语言将其表达出来。
另一些则从零开始开发了不同的架构,因此提供了具有各自优缺点的替代解决方案。
如果您知道其他类似的项目,请随时提交 issue 或 PR,我很乐意将它们添加到本页中。
我希望以下列表在未来能够大幅扩充。
类似项目
以下是我迄今为止遇到的一些类似项目的不完整列表。
如果某些术语或设计不清晰,建议参阅 ECS Back and Forth 系列文章以获取所有详细信息。
-
C:
- destral_ecs: 一个基于稀疏集 (sparse sets) 的单文件 ECS。
- Diana: 一个使用稀疏集来跟踪系统中实体的 ECS。
- Flecs: 一个多线程原型 (archetype) ECS,基于半连续数组 (semi-contiguous arrays) 而非块 (chunks)。
- lent: ECS 库中的唐纳德·特朗普。
-
C++:
- decs: 一个基于块 (chunk-based) 的原型 ECS。
- ecst: 一个多线程编译时 ECS,使用稀疏集来跟踪系统中的实体。
- EntityX: 一个基于 bitset 的 ECS,使用单个大型组件矩阵并以实体为索引。
- Gaia-ECS: 一个基于块的原型 ECS。
- Polypropylene: ECS 与动态 mixin 之间的混合解决方案。
-
C#
- Arch: 一个简单、快速且受 Unity Entities 启发的原型 ECS,支持可选的多线程。
- Entitas: C# 和 Unity 的 ECS 框架,响应式系统 (reactive systems) 即诞生于此。
- Fennecs: 那个爱你的小型原型 ECS。
- Friflo ECS: 一个专注于性能和最小化垃圾回收 (GC) 分配的原型 ECS。
- LeoECS: 简单轻量的 C# 实体组件系统框架。
- Massive ECS: 基于稀疏集的 ECS,支持回滚 (rollbacks)。
- Svelto.ECS: 一个非常有趣的平台无关且基于表 (table-based) 的 ECS 框架。
-
Go:
- gecs: 一个受
EnTT启发的基于稀疏集的 ECS。
- gecs: 一个受
-
Javascript:
- @javelin/ecs: TypeScript 中的原型 ECS。
- ecsy: 我还没有时间深入研究
ecsy的底层设计,但它看起来无论如何都很酷。
-
Perl:
- Game::Entities: 一个受
EnTT启发的用于 ECS 设计的简单实体注册表 (entity registry)。
- Game::Entities: 一个受
-
Raku:
- Game::Entities: 一个受
EnTT启发的用于 ECS 设计的简单实体注册表。
- Game::Entities: 一个受
-
Rust:
-
Zig
- zig-ecs:
EnTT的 Zig 化 版本。
- zig-ecs:
EnTT 实际应用
目录
简介
EnTT 被广泛应用于私人和商业应用程序中。由于我过去在某些文件上签署的保密协议,我甚至无法提及其中的大部分。幸运的是,也有人花时间实现了基于 EnTT 的开源项目,并且在记录它们时毫不吝啬。
以下是一份不完整的游戏、应用程序和文章列表,可作为参考。
带有“据称 (apparently)”字样的地方表示 EnTT 的使用已有记录,但作者并未发表明确声明或未直接与我联系。
如果您知道其他关于 EnTT 的资源,请随时提交 issue 或 PR。我很乐意将它们添加到本页中。
我希望以下列表在未来能够大幅扩充。
EnTT 实际应用
游戏
- Minecraft by Mojang: 当然是 那个 Minecraft,更多详情请参阅开源致谢页面。
- Minecraft Legends by Mojang: 一款动作策略游戏,用户必须战斗以保卫主世界 (Overworld)。
- Minecraft Earth by Mojang: 一款移动端增强现实 (AR) 游戏,让用户将 Minecraft 带入现实世界。
- Ember Sword: 一款现代免费 (Free-to-Play) MMORPG,具有玩家驱动的经济系统、无职业战斗系统以及稀缺且可交易的装饰性收藏品。
- 据称 Diablo II: Resurrected by Blizzard: 怪物、英雄、物品、法术,悉数复活。感谢不知名的内部人士。
- 据称 Call of Duty: Vanguard by Sledgehammer Games: 我无法确认或否认,但在致谢名单中有一个我认识的许可证。
- 据称 D&D Dark Alliance by Wizards of the Coast: 你的小队,他们的葬礼。
- TiltedEvolution by Tilted Phoques: 用于在线游玩的 Skyrim 和 Fallout 4 mod。
- Antkeeper: 一个蚁群模拟 游戏。
- Openblack: 游戏 Black & White (2001) 的开源重写版。
- Land of the Rair: 新时代 复古风格 MUD 的新后端。
- Face Smash: 一款用脸玩的游戏。
- EnTT Pacman: 一个展示如何使用
EnTT制作 Pacman 的示例。 - Wacman: 一个使用 OpenGL 的 pacman 克隆版。
- Classic Tower Defence: 一款带有自制字体的微型塔防游戏。 去看看。
- The Machine: 一款带有逻辑门和其他酷炫元素的推箱子解谜游戏。 去看看。
- EnTTPong: 一个用于展示
EnTT和 C++17 不同部分的基础游戏。 - Randballs: 简单的
SFML和EnTT实验场。 - EnTT Tower Defense: 一个面向数据 (data oriented) 的塔防示例。
- EnTT Breakout: 使用
SDL和EnTT的简单打砖块游戏示例。 - Arcade puzzle game with EnTT:
使用
SDL2和EnTT库在 C++ 中制作的街机解谜游戏。 - Snake with EnTT: 使用
SDL2和EnTT库在 C++ 中制作的简单贪吃蛇游戏。 - Mirrors lasers and robots: 一款基于镜子反射的小型塔防游戏。
- PopHead: 使用 C++ 从零制作的 2D 僵尸 RPG 游戏。
- Robotligan: 多人足球游戏。
- DungeonSlayer: 使用 C++ 从零制作的 2D 游戏。
- 3DGame: 2.5D 俯视角太空射击游戏。
- Pulcher: 受 Quake 启发的 2D 跨平台游戏。
- Destroid: 第 无数 款关于在太空中射击脏岩石的街机游戏,灵感来自 Asteroids。
- Wanderer: 一款 2D 探索类独立游戏。
- Spelunky® Classic remake: 一次真正的多平台体验,从零开始重写。
- CubbyTower: 一款使用 C++ 和实体组件系统 (ECS) 的简单塔防游戏。
- Runeterra: 使用 C++ 和一些强化学习的 Legends of Runeterra 模拟器。
- Black Sun: 驾驶你的飞船穿越庞大的 2D 开放世界。
- PokeMaster: 使用 C++ 和一些强化学习的 Pokémon Battle 模拟器。
- HomeHearth: 选择你的英雄,保护小镇,趁一切还来得及。
- City Builder Game: 一款使用 C++ 和 OpenGL 的简单城市建造游戏。
- BattleSub: 带有部分流体动力学的双人 2D 潜艇游戏。
- Crimson Rush: 一款受地牢探索 (dungeon-crawler) 和 Roguelike 启发的游戏,关于探索并尽可能长久地生存。
- Space Fight: 单屏多人街机射击游戏原型。
- Confetti Party: C++ 示例应用程序,作为使用
EnTT和SDL2的起点。 - Hellbound: 一款俯视角动作 Rogue-like 游戏,在程序生成的地狱关卡中与巨大的恶魔战斗。
- Saurian Sorcery: 一款塔防游戏,组建蜥蜴部落以抵御机器人入侵者。
- robotfindskitten: 在
Notepad.exe中运行的robotfindskitten克隆版,由EnTT提供支持。 - Orion: 外太空研究与星际观测网络(一款太空射击游戏)。
- EnTT Boids: 使用
EnTT和Raylib的简单 Boids(群集行为)实现。 - PalmRide: After Flight: 一款带有复古 Outrun 美学风格的轨道射击游戏。
- Exhibition of Speed: 打造你自己的赛车并参加比赛。
- Lichgate: 俯视角动作 Rogue-like 游戏,用户在其中解锁能力以在无尽的世界中对抗成群的敌人。
- Letalka: 小型演示游戏,屏幕上到处飞舞着飞船和子弹。
- Lichgate: 穿上强大法师的长袍,下定决心阻止无情的亡灵大军。
- You Are Circle: 一款具有高对比度矢量线条美学的 Roguelite 俯视角射击游戏。
- EnTT Dino: 仅使用
SDL2和EnTT在 C++ 中实现的 Dinosaur Game(恐龙小游戏)克隆版。 - Bim!: 一款适用于 Android 的最后一人生存 (last-man-standing) 街机在线游戏。
- MonsterWar: 使用 C++ 结合
SDL3、EnTT及其他几个库开发的塔防游戏。
引擎及类似项目
- Hazel Engine: 由 The Cherno 在其最著名的视频系列之一中创建的正在进行中的引擎。
- Aether Engine v1.1+ by Hadean: 一个专为空间划分基于智能体的模拟 (agent-based simulations) 而设计的库。
- Fling Engine: 一个专注于面向数据设计 (data oriented design) 的 Vulkan 游戏引擎。
- NovusCore: 对 World of Warcraft 模拟器的现代化重塑。
- Chrysalis: 用于 CRYENGINE 游戏的动作 RPG SDK。
- LM-Engine: 游戏引擎界的 Vim。
- Edyn: 一个组织为 ECS 的实时物理引擎。
- MushMachine: 引擎… 轰隆隆。
- Antara Gaming SDK: Komodo 游戏软件开发工具包。
- XVP: 用于 Unreal Engine 的 eXpansive Vehicle Physics 插件。
- 据称 Wisp by Team Wisp: 专为视频游戏艺术家需求构建的高级实时光线追踪渲染器。
- shiva: 具有模块化的现代 C++ 引擎。
- ImGui/EnTT editor:
一个无缝替换 (drop-in)、单文件的
EnTT实体编辑器,使用ImGui作为图形后端(附带 演示代码)。 - SgOgl: 为教育目的开发的 OpenGL 游戏引擎库。
- Lumos: 使用 C++ 以及 OpenGL 和 Vulkan 编写的游戏引擎。
- Silvanus: Silvanus Fusion 360 盒子生成器。
- Lina Engine: 一个开源、模块化、小巧且快速的 C++ 游戏引擎,旨在开发 3D 桌面游戏。
- Spike: 一个甚至能在烤面包机上运行的强大游戏引擎。
- Helena Framework: 一个用于后端开发的现代 C++17 框架。
- Unity/EnTT: 使用
EnTT和Unity作为渲染引擎的原生模拟层技术演示。 - OverEngine: 一个过度工程化 (overengineered) 的游戏引擎。
- Electro: 高度重视渲染的高性能 3D 游戏引擎。
- Kawaii: 一个现代的面向数据的游戏引擎。
- Becketron: 主要使用 C++ 编写的游戏引擎。
- Spatial Engine: 基于 Google Filament 渲染引擎创建的跨平台引擎。
- Kaguya: D3D12 渲染引擎。
- OpenAWE: Alan Wake Engine 的开源实现。
- Nazara Engine: 快速、跨平台、面向对象的 API,旨在帮助开发者的日常工作。
- Billy Engine: 某种基于
SDL2和EnTT的 2D 引擎。 - Ducktape: 一个开源的 C++ 2D 和 3D 游戏引擎,专注于快速和强大。
- The Worst Engine: 一个基于 OpenGL 的游戏引擎。
- Ecsact: 一种旨在描述 ECS 的语言,带有基于
EnTT的 运行时实现。 - AGE (Arc Game Engine): 一个用于构建 2D 和 3D 实时渲染及交互内容的开源引擎。
- Kengine: Koala engine 是一个完全作为 entity-component-system 实现的游戏引擎。
- Scion2D: 附带 YouTube 系列教程 的 2D 游戏引擎。
- EnTT Editor: 一个用于
EnTT库的编辑器,将其内置的反射系统与ImGui结合。 - Era Game Engine: 一个现代的基于 ECS 的游戏引擎。
- Core SDK of Trollworks engine: 基于拖延症 (procrastination) 的 2D 游戏引擎。
- Rocky: 3D 地理空间应用引擎。
- Donner: 带有 CSS3 的现代 C++20 SVG2 渲染 API。
- Coral Engine: 开源的学生引擎,带有使用 C++ 和可视化脚本制作游戏的工具。
- Star Engine: 一个高级 C++ DirectX 11 游戏引擎。
- Darmok: 另一个 C++ 游戏引擎。
- Magique: 面向程序员(或尚未成为程序员的人)的 2D 游戏引擎。
- Physecs: 基于
EnTT构建的实时 3D 刚体物理模拟。 - KODZA: 一个正在进行中的游戏引擎。
- Omnax: 一个正在开发中的多用途 3D 引擎,适用于
macOS,使用EnTT作为 ECS。
文章、视频与博客文章
- 我的个人 博客 上有 一些文章 是关于
EnTT的,供那些想对本项目了解 更多 的人阅读。 - 由 The Cherno 制作的 Game Engine 系列(不仅关于
EnTT,也关于 ECS 的一般使用):- Intro to EnTT.
- Entities and Components.
- The ENTITY Class.
- Camera Systems.
- Scene Camera.
- Native Scripting.
- Native Scripting (now with virtual functions!).
- Scene Hierarchy Panel.
- Properties Panel.
- Camera Component UI.
- Drawing Component UI.
- Transform Component UI.
- Adding/Removing Entities and Components UI.
- Saving and Loading Scenes.
- … 等等。 去看看 The Cherno 的 Game Engine Series 以获取更多视频。
- 由 dwjclark11 制作的 Game Engine 系列(不仅仅是
EnTT,但包含大量相关内容): - 由 linkdd 撰写的 Warmonger Dynasty 开发日志系列:一篇有趣的(也)使用 EnTT 开发游戏的演练。
- Use EnTT When You Need An ECS by Thomas: 我无法说得比这更好了。
- Space Battle: Huge edition: 完全从零构建的巨型太空战。
- Space Battle: 基于
UE4构建的巨型太空战。 - Experimenting with ECS in UE4:
关于
UE4和EnTT的有趣文章。 - Implementing ECS architecture in UE4: 巨型太空战。
- Conan Adventures (SFML and EnTT in C++):
使用
SFML、EnTT、Conan和CMake在现代 C++ 中创建项目。 - Adding EnTT ECS to Chrysalis:
一篇博客文章(及其
后续),关于将
EnTT集成到Chrysalis(一个用于 CRYENGINE 游戏的动作 RPG SDK)中。 - Creating Minecraft in One Week with C++ and Vulkan: 尝试在一周内使用自定义 C++ 引擎和 Vulkan 重现 Minecraft(包含代码)。
- Ability Creator: 由 Eric Hildebrand 撰写的项目回顾。
- EnTT Entity Component System Gaming Library:
GameFromScratch.com 上的
EnTT。 - Custom C++ server for UE5 及其关于玩家机器人和完整外部 ECS 的 后续 剧集:为 MMO(RPG) 优化的服务器,一个绝对值得关注的系列。
其他应用
- ArcGIS Runtime SDKs by
Esri: 他们使用
EnTT作为内部 ECS 和跨平台 C++ 渲染引擎。这些 SDK 被大量企业定制应用使用,也被 Esri 用于其自身的公共应用程序,例如 Explorer、 Collector 和 Navigator。 - OneArc: 许可证 不会撒谎。他们的产品以某种方式使用了 EnTT,但 具体方式 未知。
- FASTSUITE Edition 2
by Cenit: 他们使用
EnTT来驱动其模拟,即机器人控制器模拟器与渲染器之间的通信。 - Ragdoll: Autodesk Maya 2020 的实时物理插件。
- Project Lagrange: 由 Adobe 开发的强大几何处理库。
- AtomicDEX: 一个集安全钱包和非托管去中心化交易所于一身的应用程序。
- 据称 NIO: 曾有过合作对
EnTT进行一些修改,当时它被用于内部项目。 - 据称 Tieto: 他们发布了一份招聘信息,其中
EnTT被列为其软件栈的一部分。 - Sequentity: 适用于 C++ 和
ImGui(结合Magnum和EnTT)的类 MIDI 音序器/跟踪器。 - EnTT meets Sol2: 免费提供的示例,展示如何结合
EnTT和Sol2。 - Godot meets EnTT:
一个关于如何在
Godot中使用EnTT的简单示例。 - Godot and GameNetworkingSockets meet EnTT:
一个关于如何在
Godot中使用EnTT和GameNetworkingSockets的简单示例。 - MatchOneEntt: 将 Match One(针对
Entitas-CSharp)移植的版本。 - GitHub 上还包含
许多其他示例,展示了
EnTT的使用,如果感兴趣可以从中汲取灵感。
Lectures
Lectures notes and thoughts
CMU 15445 Intro to Database Systems
#01 Relation Model & Algebra
- Concepts
- A database is an organized collection of inter-related data that models some aspect of the real-world.
- A data model is a collection of concepts for describing the data in database.
- Relation (most common)
- NoSQL (kv, doc, graph)
- Array / Matrix / Vector (for ML)
- A schema is a description of a particular collection of data, using a given data model.
- This defines the structure of data for a data model
- Otherwise, you have random bits with no meaning
- Relation Algebra


#02 Modern SQL
- Relation Languages
- Data Manipulation Language (DML)
- SELECT, UPDATE, DELETE, …
- Data Define Language (DDL)
- CREATE …
- Data Control Language (DCL)
- GRANT …
- Aggregates
- AVG(COL): The average of the values in COL
- MIN(COL): The minimum value in COL
- MAX(COL): The maximum value in COL
- SUM(COL): The sum of the values in COL
- COUNT(COL): The number of tuples in the relation


- String Operations
The SQL standard says that strings are case sensitive and single-quotes only. There are functions to manipulate strings that can be used in any part of a query.
Pattern Matching: The LIKE keyword is used for string matching in predicates.
- “%” matches any substrings (including empty).
- “_” matches any one character.
Examples of standard string functions include SUBSTRING(S, B, E) and UPPER(S).
Concatenation: Two vertical bars (“||”) will concatenate two or more strings together into a single string.
- Date and Time
Databases generally want to keep track of dates and time, so SQL supports operations to manipulate DATE and TIME attributes. These can be used as either outputs or predicates.
Specific syntax for date and time operations can vary wildly across systems.
- Output Control
- ORDER BY <column> [ASC|DESC]
- FETCH [FIRST|{NEXT}] <count> ROWS ONLY {OFFSET <count>} {WITH TIES} (ANSI SQL)
- LIMIT <count> OFFSET <count> (MySQL/SQLite)
> SELECT * FROM employee;
|name|salary|
-------------
| A | 1000 |
| B | 1300 |
| C | 1100 |
| D | 1100 |
| E | 1400 |
> SELECT salary FROM employee FETCH FIRST 3 ROWS WITH TIES;
|salary|
--------
| 1000 |
| 1300 |
| 1100 |
| 1100 | <- TIES
- Window Functions
A window function performs “sliding” calculation across a set of tuples that are related. Window functions are similar to aggregations, but tuples are not collapsed into a singular output tuple.
Aggregations:
|name|salary|age|
-----------------
| A | 1000 |23 |
| B | 1300 |22 |
| C | 1100 |23 |
| D | 1100 |45 |
| E | 1400 |22 |
--- Aggregate by age ---
|name |salary |age|
-----------------------
| A,C | 1000,1100 |23 |
| B,E | 1300,1400 |22 |
| D | 1100 |45 |
--- Mean on salary ---
|salary|age|
------------
| 1050 |23 |
| 1350 |22 |
| 1100 |45 |
Window:
|name|salary|age|
-----------------
| A | 1000 |23 |
| B | 1300 |22 |
| C | 1100 |23 |
| D | 1100 |45 |
| E | 1400 |22 |
--- Window over age ---
|name|salary|age|
-----------------
| A | 1000 |23 |
| C | 1100 |23 |
-----------------
| B | 1300 |22 |
| E | 1400 |22 |
-----------------
| D | 1100 |45 |
--- ROW_NUMBER()/RANK(salary) ---
|name|salary|age|row_number
---------------------------
| A | 1000 |23 |1
| C | 1100 |23 |2
---------------------------
| B | 1300 |22 |1
| E | 1400 |22 |2
---------------------------
| D | 1100 |45 |1

- Nested Queries

Nested Query Results Expressions:
- ALL: Must satisfy expression for all rows in sub-query.
- ANY: Must satisfy expression for at least one row in sub-query.
- IN: Equivalent to =ANY().
- EXISTS: At least one row is returned

- Lateral Joins
The LATERAL operator allows a nested query to reference attributes in other nested queries that precede it. You can think of lateral joins like a for loop that allows you to invoke another query for each tuple in a table.

SELECT * FROM course AS c,
|cid |name
-------------
|15-445|Database System
|15-721|Advanced Database System
|15-826|Data Mining
LATERAL (SELECT COUNT(*) AS cnt FROM enrolled
WHERE enrolled.cid = c.cid) AS t1,
-- For each cid in c, execute
-- `SELECT COUNT(*) AS cnt FROM enrolled WHERE enrolled.cid = c.cid`
|cid |name |cnt
------------------------------------
|15-445|Database System |2
|15-721|Advanced Database System|3
|15-826|Data Mining |2
--
LATERAL (SELECT AVG(gpa) AS avg FROM student AS s
JOIN enrolled AS e ON s.sid = e.sid
WHERE e.cid = c.cid) AS t2;
-- For each cid in c, execute
-- `SELECT AVG(gpa) AS avg FROM student AS s JOIN enrolled AS e ON s.sid = e.sid WHERE e.cid = c.cid`
|cid |name |cnt|avg
----------------------------------------
|15-445|Database System |2 |3.2
|15-721|Advanced Database System|3 |3.4
|15-826|Data Mining |2 |3.6
- Common Table Expressions
Common Table Expressions (CTEs) are an alternative to windows or nested queries when writing more complex queries. They provide a way to write auxiliary statements for use in a larger query. A CTE can be thought of as a temporary table that is scoped to a single query.
WITH cteName AS (
SELECT 1
)
SELECT * FROM cteName;
|*|
---
|1|
Bind output columns to names before the AS:
WITH cteName (col1, col2) AS (
SELECT 1, 2
)
SELECT col1 + col2 FROM cteName;
Multiple CTE declarations in single query:
WITH cte1 (col1) AS (SELECT 1), cte2 (col2) AS (SELECT 2)
SELECT * FROM cte1, cte2;
Adding the RECURSIVE keyword after WITH allows a CTE to reference itself. This enables the implementation of recursion in SQL queries. With recursive CTEs, SQL is provably Turing-complete, implying that it is as computationally expressive as more general purpose programming languages (ignoring the fact that it is a bit more cumbersome).
Print the sequence of numbers from 1 to 10:
WITH RECURSIVE cteSource (counter) AS (
( SELECT 1 )
UNION
( SELECT counter + 1 FROM cteSource
WHERE counter < 10 )
)
SELECT * FROM cteSource;
Homework 1

Q2: Find all successful coaches who have won at least one medal. List them in descending order by medal number, then by name alphabetically:
Details: A medal is credited to a coach if it shares the same country and discipline with the coach, regardless of the gender or event. Consider to use winner_code of one medal to decide its country.
select c.name as COACH_NAME, count(*) as MEDAL_NUMBER
from coaches as c
join (
select m.discipline, t.country_code from medals as m join
(
select code, country_code from teams
union all
select code, country_code from athletes
) as t on m.winner_code = t.code
) as o on c.country_code = o.country_code
and c.discipline = o.discipline
group by c.name
order by MEDAL_NUMBER desc, COACH_NAME;
Q3: Find all athletes in Judo discipline, and also list the number of medals they have won. Sort output in descending order by medal number first, then by name alphabetically:
Details: The medals counted do not have to be from the Judo discipline, and also be sure to include any medals won as part of a team. If an athlete doesn’t appear in the athletes table, please ignore him/her. Assume that if a team participates in a competition, all team members are competing.
with medals_cnt as ( -- athlete_code, cnt
select athlete_code, sum(cnt) as cnt from
(select athletes.code as athlete_code, count(*) as cnt
from athletes, medals
where athletes.code = medals.winner_code
group by athletes.code
union all -- row duplicated is allowed
select athletes_code as athlete_code, count(*) as cnt
from teams, medals
where teams.code = medals.winner_code
group by athletes_code)
group by athlete_code
)
select name as ATHLETE_NAME,
(case when cnt is not null then cnt else 0 end) as MEDAL_NUMBER
from athletes left join medals_cnt -- use left join to keep all records in athletes
on athletes.code = medals_cnt.athlete_code
where athletes.disciplines like '%Judo%'
order by MEDAL_NUMBER desc, ATHLETE_NAME;
Q4: For all venues that have hosted Athletics discipline competitions, list all athletes who have competed at these venues, and sort them by the distance from their nationality country to the country they represented in descending order, then by name alphabetically.
Details: The athletes can have any discipline and can compete as a team member or an individual in these venues. The distance between two countries is calculated as the sum square of the difference between their latitudes and longitudes. Only output athletes who have valid information. (i.e., the athletes appear in the athletes table and have non-null latitudes and longitudes for both countries.) Assume that if a team participates in a competition, all team members are competing.
with comp as (
select participant_code, participant_type
from results, venues
where results.venue = venues.venue
and venues.disciplines like '%Athletics%'
), a as (
select *
from athletes
where code in
(select distinct participant_code
from
(select participant_code
from comp
where participant_type = 'Person'
union
select athletes_code as participant_code
from teams, comp
where comp.participant_type = 'Team'
and comp.participant_code = teams.code))
)
select
name as ATHLETE_NAME,
country_code as REPRESENTED_COUNTRY_CODE,
nationality_code as NATIONALITY_COUNTRY_CODE
from
(select t.*, countries.Latitude as nationality_latitude, countries.Longitude as nationality_longitude
from
(select a.*, countries.Latitude as country_latitude, countries.Longitude as country_longitude
from a left join countries on a.country_code = countries.code) as t
left join countries on t.nationality_code = countries.code
where nationality_latitude is not null
and nationality_longitude is not null
and country_latitude is not null
and country_longitude is not null)
order by
(country_latitude - nationality_latitude)^2 + (country_longitude - nationality_longitude)^2 desc, athlete_name;
Q5: For each day, find the country with the highest number of appearances in the top 5 ranks (inclusive) of that day. For these countries, also list their population rank and GDP rank. Sort the output by date in ascending order:
Hints: Use the result table, and use the participant_code to get the corresponding country. If you cannot get the country information for a record in the result table, ignore that record.
Details: When counting appearances, only consider records from the results table where rank is not null. Exclude days where all rank values are null from the output. In case of a tie in the number of appearances, select the country that comes first alphabetically. Keep the original format of the date. Also, DON’T remove duplications from results table when counting appearances. (see Important Clarifications section).
with country_rank as (
select
code,
rank() over (order by "GDP ($ per capita)" desc) as gdp_rank,
rank() over (order by "Population" desc) as population_rank
from
countries
)
select
t1.date as DATE,
t1.country_code as COUNTRY_CODE,
t1.cnt as TOP5_APPEARANCES,
country_rank.gdp_rank as GDP_RANK,
country_rank.population_rank as POPULATION_RANK
from
(select *,
row_number() over (partition by date order by date, cnt desc) as row_number
from (
select date,
country_code,
count(*) as cnt
from (
select date, rank, country_code
from results, athletes
where results.participant_type = 'Person'
and results.participant_code = athletes.code
union all
select date, rank, country_code
from results, teams
where results.participant_type = 'Team'
and results.participant_code = teams.code)
where rank <= 5 group by date, country_code)) as t1, country_rank
where t1.row_number = 1 and country_rank.code = t1.country_code
order by date;
Q6: List the five countries with the greatest improvement in the number of gold medals compared to the Tokyo Olympics. For each of these five countries, list all their all-female teams. Sort the output first by the increased number of gold medals in descending order, then by country code alphabetically, and last by team code alphabetically.
Details: When calculating all-female teams, if the athletes_code in a record from the teams table is not found in the athletes table, please ignore this record as if it doesn’t exist.
with t as (
select code, country_code from teams group by code, country_code
) -- team may duplicate
select * from (
select
t1.country_code as COUNTRY_CODE,
t1.paris_gold - t2.gold_medal as INCREASED_GOLD_MEDAL_NUMBER,
from (
select
country_code,
count(*) as paris_gold
from (
select country_code
from medals, athletes
where medals.winner_code = athletes.code and medal_code = 1
union all
select country_code
from medals, t
where medals.winner_code = t.code and medal_code = 1
)
group by country_code
) as t1, tokyo_medals as t2
where t1.country_code = t2.country_code
order by INCREASED_GOLD_MEDAL_NUMBER desc
limit 5
) as i1,
lateral (
select teams.code as TEAM_CODE
from teams, athletes
where teams.athletes_code = athletes.code and teams.country_code = i1.country_code
group by teams.code
having SUM(1- gender) = 0 -- mem: 0, women: 1 [all female = 'sum(1 - gender) = 0']
)
order by INCREASED_GOLD_MEDAL_NUMBER desc, COUNTRY_CODE, TEAM_CODE;
#03 Database Storage: Files & Pages
- Storage Interface
Overview:
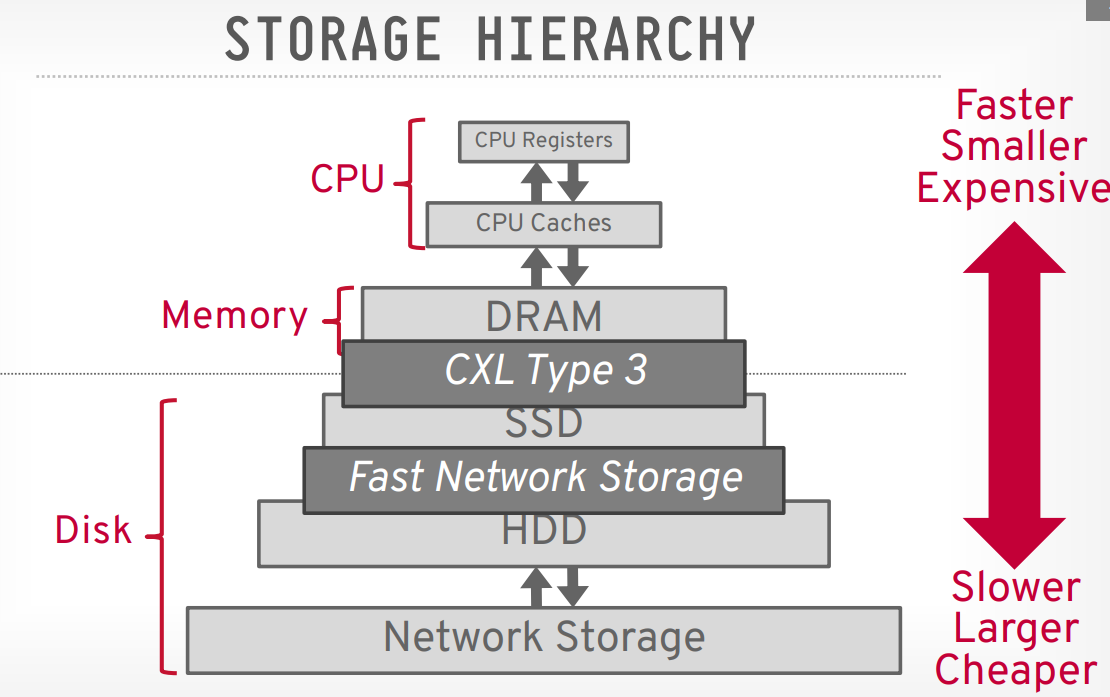
Access time comparation:

- Use
mmapor not?
- You never want to use mmap in your DBMS if you need to write.
- The DBMS (almost) always wants to control things itself and can do a better job at it since it knows more about the data being accessed and the queries being processed.
But it is possible to use by using:
madvise: Tells the OS know when you are planning on reading certain pages.mlock: Tells the OS to not swap memory ranges out to disk.msync: Tells the OS to flush memory ranges out to disk.
Even though the system will have functionalities that seem like something the OS can provide, having the DBMS implement these procedures itself gives it better control and performance.
- Files
In its most basic form, a DBMS stores a database as files on disk. Some may use a file hierarchy, others may use a single file (e.g., SQLite).
The DBMS’s storage manager is responsible for managing a database’s files. It represents the files as a collection of pages. It also keeps track of what data has been read and written to pages as well how much free space there is in these pages (e.g. free-space map).
- Pages
-
Fixed-size: Typically 4 to 16KB. Most DBMSs uses fixed-size pages to avoid the engineering overhead needed to support variable-sized pages. We really don’t want to deal with variable-sized pages after dealing with variable-sized records.
- Read-only workloads may have larger page sizes.
-
Self-contained: Some systems will require that pages are self-contained, meaning that all the information needed to read each page is on the page itself. This is very useful in disaster recovery, as it can still recover some data from the remaining half when half of the disk is damaged.
-
Page Directory: DBMS maintains special pages, called page directory, to track locations of data pages, the amount of free space on each page, a list of free/empty pages and the page type. These special pages have one entry for each database object.
Every page includes a header that records metadata about the page’s contents:
- Page size.
- Checksum.
- DBMS version.
- Transaction visibility.
- …
There are serval ways to lay out records in a page:
- Slotted Pages
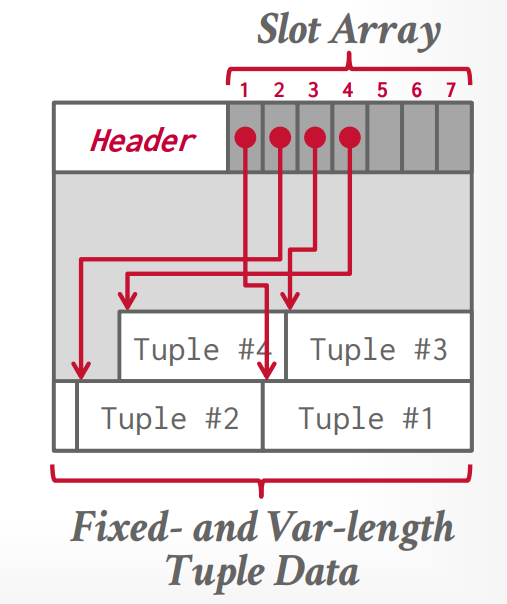
Header keeps track of the number of used slots, the offset of the starting location of the last used slot, and a slot array, which keeps track of the location of the start of each tuple.
To add a tuple, the slot array will grow from the beginning to the end, and the data of the tuples will grow from end to the beginning. The page is considered full when the slot array and the tuple data meet.
To delete a tuple, the entry in the slot array will be wiped out. We can shift the remaining tuples to maintain they are consecutive at the end of page.
- Log Structured
// Covered in the next lecture.
- Tuples
Each tuple may have a tuple header to contains metadata about the tuple; it can be constructed of:
- Transaction visibility.
- Bitmap for NULL values.
- …
Unique Identifier is required to identify a tuple and the most common format is page_id + (offset or slot)
- Denormalized Tuple Data: If two tables are related, the DBMS can “pre-join” them, so the tables end up on the same page. This makes reads faster since the DBMS only has to load in one page rather than two separate pages. However, it makes updates more expensive since the DBMS needs more space for each tuple.